In Fevre Dream, George R. R. Martin writes about a fat bearded guy with a large appetite and a passion for food that loves to be a boat captain. Write what you know, they say. Anyways, this book about vampires in the bayou feels really dated. It has been described as "Bram Stoker meets Mark Twain", so you can imagine how much; written in 1982, it feels like written by a Lovecraft contemporary.
I love Lovecraft, but it gets worse. None of the characters in the book except maybe the main protagonist are likable. They come off as either high and mighty or ridiculously servile. And I understand that in a story where vampires have a master that can be all controlling this is to be expected, but at the same time the hero of the story, without being "compelled", still acts like a servant, enthralled (pardon my pun) by the aristocratic majesty of his vampire friend. One has to get through pages of tedious description of architecture and food and home improvement to get to the succulent part (OK, couldn't help that one) but which then feels cloyed and unsatisfactory. So many interesting characters get just a few scenes, while most of the book is how much the captain loves his food and his ship. And while it discusses some social issues, like slavery and how easily people died or disappeared at the time, it also promotes this idea of personal nobility that justifies other people getting used. This focus on aristocracy is something one sees in A Song of Fire and Ice as well, but less pronounced.
I could have given it an average to good rating if not for the abysmal ending. While at the beginning I had applauded the way the author was building tension and apparently providing a solution only to snatch it away at the last moment, the ending destroys all of it by pretty much invalidating much of the foil of the characters and a major part of the story. The time displacement also accentuates this feeling, as I thought "waited so much for this?!", and by that I mean both me as a reader and the main character in the book.
Bottom line: uninteresting vampires in a slow paced story that probably appeals to Martin fans only. It manages to insert the reader in the eighteen hundreds and the river boat mentality, but there is nothing much else to learn or enjoy in the book beyond that.
Started with the idea of a project that would use user configurable queries to do Google searches, store the information in the results and then perform various data analysis on them and display them based on what the user wants. However, I first implemented a Google authentication and then went to write some theoretical posts. Lastly, I've upgraded the project from .NET Core 1.0 to version 1.1.
Well, it took me a while to get here because I was at a crossroads. I like the idea of dependency injectable services to do data access. At the same time there is the entire Entity Framework tutorial path that kind of wants to strongly integrate EF with my projects. I mean, if I have a service that gives me the list of all items in the database and then I want to get only a few items, it would be bad design to filter the entire list. As such, I would have to write a different method that allows me to get the items based on some kind of filters. On the other hand, Entity Framework code looks just like that "give me all you have, filtered by this" which is then translated into an efficient query to the database. One possibility would be to have my service return IQueryable <T>, so I could also use the system to generate the database code on the fly.
The Design
I've decided on the service architecture, against an EF type IQueryable way, because I want to be able to replace that service with anything, including something that doesn't work with a database or something that doesn't know how to dynamically create queries. Also, the idea that the service methods will describe exactly what I want appeals to me more than avoiding a bit of duplicated code.
Another thing to define now is the method through which I will implement the dependency injection. Being the control freak that I am, I would go with installing my own library, something like SimpleInjector, and configure it myself and use it explicitly. However, ASP.Net Core has dependency injection included out of the box, so I will use that.
As defined, the project needs queries to pass on to Google and a storage service for the results. It needs data services to manage these entities, as well as a service to abstract Google itself. The data gathering operation itself cannot be a simple REST call, since it might take a while, it must be a background task. The data analysis as well. So we need a sort of job manager.
As per a good structured design, the data objects will be stored in a separate project, as well as the interfaces for the services we will be using.
Some code, please!
Well, start with the code of the project so far: GitHub and let's get coding.
Before finding a solution to actually run the background code in the context of ASP.Net, let's write it inside a class. I am going to add a folder called Jobs and add a class in it called QueryProcessor with a method ProcessQueries. The code will be self explanatory, I hope.
publicvoid ProcessQueries() { var now = _timeService.Now; var queries = _queryDataService.GetUnprocessed(now); var contentItems = queries.AsParallel().WithDegreeOfParallelism(3) .SelectMany(q => _contentService.Query(q.Text)); _contentDataService.Update(contentItems); }
So we get the time - from a service, of course - and request the unprocessed queries for that time, then we extract the content items for each query, which then are updated in the database. The idea here is that, for the first time a query is defined or when the interval from the last time the query was processed, the query will be sent to the content service from which content items will be received. These items will be stored in the database.
Now, I've kept the code as concise as possible: there is no indication yet of any implementation detail and I've written as little code as I need to express my intention. Yet, what are all these services? What is a time service? what is a content service? Where are they defined? In order to enable dependency injection, we will populate all of these fields from the constructor of the query processor. Here is how the class would look in its entirety:
using ContentAggregator.Interfaces; using System.Linq;
publicvoid ProcessQueries() { var now = _timeService.Now; var queries = _queryDataService.GetUnprocessed(now); var contentItems = queries.AsParallel().WithDegreeOfParallelism(3) .SelectMany(q => _contentService.Query(q.Text)); _contentDataService.Update(contentItems); } } }
Note that the services are only defined as interfaces which we declare in a separate project called ContentAggregator.Interfaces, referred above in the usings block.
Let's ignore the job processor mechanism for a moment and just run ProcessQueries in a test method in the main controller. For this I will have to make dependency injection work and implement the interfaces. For brevity I will do so in the main project, although it would probably be a good idea to do it in a separate ContentAggregator.Implementations project. But let's not get ahead of ourselves. First make the code work, then arrange it all nice, in the refactoring phase.
Implementing the services
I will create mock services first, in order to test the code as it is, so the following implementations just do as little as possible while still following the interface signature.
They are all transient, meaning that for each request of an implementation the system will just create a new instance. Another popular method is AddSingleton.
Using dependency injection
So, now I have to instantiate my query processor and run ProcessQueries.
One way is to set QueryProcessor as a service. I extract an interface, I add a new binding and then I give an interface as a parameter of my controller constructor:
In fact, I don't even have to declare an interface. I can just use services.AddTransient<QueryProcessor>(); in ConfigureServices and it works as a parameter to the controller.
But what if I want to use it directly, resolve it manually, without injecting it in the controller? One can use the injection of a IServiceProvider instead. Here is an example:
Yet you still need to use services.Add... in ConfigureServices and inject the service provider in the constructor of the controller.
There is a way of doing it completely separately like this:
var serviceProvider = new ServiceCollection() .AddTransient<ITimeService, TimeService>() .AddTransient<IContentDataService, ContentDataService>() .AddTransient<IContentService, ContentService>() .AddTransient<IQueryDataService, QueryDataService>() .AddTransient<QueryProcessor>() .BuildServiceProvider(); var queryProcessor = serviceProvider.GetService<QueryProcessor>();
This would be the way to encapsulate the ASP.Net Dependency Injection in another object, maybe in a console application, but clearly it would be pointless in our application.
The complete source code after these modifications can be found here. Test the functionality by going to /test on your local server after you start the app.
I've seen several very positive reviews of The Call, by Peadar Ó Guilín so I started reading it. A few hours later I had finished it. It was good: well written, with compelling characters, a fresh idea and a combination of young adult and body horror mixed with Irish mythology that hooked me immediately. I was sorry it had ended and simultaneously hoped for and cursed the idea of "trilogizing" it.
So the book follows this girl who can't use her legs because of polio. She is a happy child until her parents explain to her the realities: Ireland is separated from the world by an impassible barrier and the Aes Sidhe, the Irish fairies, are kidnapping each adolescent kid once, hunt them and hurt them in horrific ways, as revenge for the Irish banishing them to a hellish world. When "the call" comes, the child disappears, leaving back anything that is not part of their bodies and returns in 184 seconds. However, they experience an entire day in the colorless, ugly and cruel world of the Sidhe where they have to fight for their lives. In response, the Irish nation organizes in order to survive, with mandatory child births and training centers where teens are being prepared for the call in hope they will survive.
One might think this is something akin to young adult novels like The Maze, but this is much better. The main character has to overcome her disability as well as the condescending pity or disgust of others. She must manage her crush on a boy in school as well as the rules, both societal and self imposed, about expressing emotion in a world where any friend you have may just disappear in front of you and returned a monster or dead. Her friends are equally well defined, without the book being overly descriptive. The fairies have the ability to change the human body with a mere touch, so even the few kids who survive returned mentally and bodily deformed. The gray world itself is filled with horrors, with an ecosystem of carnivorous plants and animals that are actually made of altered humans, from hunting dogs and mounts to worms and spiders which somehow still maintain some sort of sentience so they can feel pain. I found the Aes Sidhe incredibly compelling: they are incredibly beautiful people and are full of joy and merriment, even as they maim and torture and kill and even when they are themselves in pain or dying, a race of psychotic vengeful people that know nothing but hate.
So I really liked the book and recommend it highly.
People who know me often snicker whenever someone utters "refactoring" nearby. I am a strong proponent of refactoring code and I have feelings almost as strong for the managers who disagree. Usually they have really stupid reasons for it, too. However, speaking with a colleague the other day, I realized that refactoring can be bad as well. So here I will explore this idea.
Why refactor at all?
Refactoring is the process of rewriting code so that it is more readable and maintainable. It does not mean writing code to be readable and maintainable from the beginning and it does not mean that doing it you accept your code was not good when you first wrote it. Usually the scope of refactoring is larger than localized bits of code and takes into account several areas in your software. It also has the purpose of aligning your codebase with the inevitable scope creep in any project. But more than this, its primary use is to make easy the work of people that will work on the code later on, be it yourself or some colleague.
I was talking with this friend of mine and he explained to me how, especially in the game industry, managers are reluctant to spend resources in cleaning old code before actually starting work on new one, since release dates come fast and technologies change rapidly. I replied that, to me, refactoring is not something to be done before you write code, but after, as a phase of the development process. In fact, there was even a picture showing it on a wheel: planning, implementing, testing and bug fixing, refactoring. I searched for it, but I found so many other different ideas that I've decided it would be pointless to show it here. However, most of these images and presentation files specified maintenance as the final step of a software project. For most projects, use and maintenance is the longest phase in the cycle. It makes sense to invest in making it easier for your team.
So how could any of this be bad?
Well, there are types of projects that are fire and forget, they disappear after a while, their codebase abandoned. Their maintenance phase is tiny or nonexistent and therefore refactoring the code has a limited value. But still it is not a case when refactoring is wrong, just less useful. I believe that there are situations where refactoring can have an adverse effect and that is exactly the scenario my friend mentioned: before starting to code. Let me expand on that.
Refactoring is a process of rewriting code, which implies you not only have a codebase you want to rewrite, but also that you know how to do it. Except very limited cases where some project is bought by another company with a lot more experienced developers and you just need to clean up garbage, there is no need to touch code that you are just beginning to understand. To refactor after you've finished a planned development phase (a Scrum sprint, for example, or a completed feature) is easy, since you understand how the code was written, what the requirements have become, maybe you are lucky enough to have unit tests on the working code, etc. It's the now I have it working, let's clean it up a little phase. Alternately, doing it when you want to add things is bad because you barely remember what and who did anything. Moreover, you probably want to add features, so changing the old code to accommodate adding some other code makes little sense. Management will surely not only not approve, but even consider it a hostile request from a stupid techie who only cares about the beauty of code and doesn't understand the commercial realities of the project. So suggest something like this and you risk souring the entire team on the prospect of refactoring code.
Another refactoring antipattern is when someone decides the architecture needs to be more flexible, so flexible that it could do anything, therefore they rearchitect the whole thing, using software patterns and high level concepts, but ignoring the actual functionality of the existing code and the level of seniority in their team. In fact, I wouldn't even call this refactoring, since it doesn't address problems with code structure, but rewrites it completely. It's not making sure your building is sturdy and all water pipes are new, it's demolishing everything, building something else, then bringing the same furniture in. Indeed, even as I like beautiful code, doing changes to it solely to make it prettier or to make you feel smarter is dead wrong. What will probably happen is that people will get confused on the grand scheme of things and, without expensive supervision in terms of time and other resources, they will start to cut corners and erode the architecture in order to write simpler code.
There is a system where software is released in "versions". So people just write crappy code and pile features one over the other, in the knowledge that if the project has success, then the next version will be well written. However, that rarely happens. Rewriting money making code is perceived as a loss by the financial managers. Trust me on this: the shitty code you write today will haunt you for the rest of the project's lifetime and even in its afterlife, when other projects are started from cannibalized codebases. However, I am not a proponent of writing code right from the beginning, mostly because no one actually knows what it should really do until they end writing it.
Refactoring is often associated with Test Driven Development, probably because they are both difficult to sell to management. It would be a mistake to think that refactoring is useful only in that context. Sure, it is a best practice to have unit tests on the piece of code you need to refactor, but let's face it, reality is hard enough as it is.
Last, but not least, is the partial or incomplete refactoring. It starts and sometime around the middle of the effort new feature requests arrive. The refactoring is "paused", but now part of your code is written one way and the rest another. The perception is that refactoring was not only useless, but even detrimental. Same when you decide to do it and then allow yourself to avoid it or postpone it and you do it badly enough it doesn't help at all. Doing it for the sake of saying you do it is plain bad.
The right time and the right people
I personally believe that refactoring should be done at the end of each development interval, when you are still familiar with the feature and its implementation. Doing it like this doesn't even need special approval, it's just the way things are done, it's the shop culture. It is not what you do after code review - simple code cleaning suggested by people who took five minutes to look it over - it is a team effort to discuss which elements are difficult to maintain or are easy to simplify or reuse or encapsulate. It is not a job for juniors, either. You don't grab the youngest guy in the team and you let him rearrange the code of more experienced people, even if that seems to teach the guy a lot. Also, this is not something that senior devs are allowed to do in their spare time. They might like it, but it is your responsibility to care about the project, not something you expect your team to do when you are too lazy or too cheap. Finally, refactoring is not an excuse to write bad code in the hope you will fix it later.
By the way I am talking about this you probably believe I've worked in many teams where refactoring was second nature and no one would doubt its utility. You would be wrong. Because it is poorly understood, the reaction of non technical people in a software team to the concept of refactoring usually falls in the interval between condescension and terror. Money people don't understand why change something that works, managers can't sell it as a good thing, production and art people don't care. Even worse, most technical people will rather write new stuff than rearrange old stuff and some might even take offense at attempts to make "their code" better. But they will start to mutter and complain a lot when they will get to the maintenance phase or when they will have to write features over old code, maybe even theirs, and they will have difficulty understanding why the code is not written in a way in which their work would be easy. And when managers will go to their dashboards and compare team productivity they will raise eyebrows at a chart that shows clear signs of slowing down.
Refactoring has a nasty side effect: it threatens jobs. If the code would be clean and any change easy to perform, then there will be a lot of pressure on the decision makers to justify their job. They will have to come with relevant new ideas all the time. If the effort to maintain code or add new features is small, there will be pressure on developers to justify their job as well. Why keep a large team for a project that can easily accommodate a few junior devs that occasionally add something. Refactoring is the bane of the type of worker than does their job confusingly enough that only they can continue to do it or pretend to be managing a difficult project, but they are the ones that make it be so. So in certain situations, for example in single product companies, refactoring will make people fear they will be made redundant. Yet in others it will accelerate the speed of development for new projects, improve morale and win a shit load of money.
So my parting thoughts are these: sell it right and do it right! Most likely it will have a positive effect on the entire project and team. People will be happier and more productive, which means their bosses will be happier and filthy richer. Do it badly or sell it wrong and you will alienate people and curse shitty code for as long as you work there.
Inspired by the writings of classics like Asimov, Heinlein and Clarke, Arkwright is a short book that spans several centuries of space exploration and colonization, so after a very positive review on Io9, I've decided to read it. My conclusion: a reedited collection of poorly written shorts stories, it is optimistic and nostalgic enough to be read without effort, but it doesn't really teach anything. Like many of the works it was inspired from, it feels anachronistic, yet it was published in 2016, which makes me wonder why did anyone review this so positively. Perhaps if reviews would not word things so bombastically: "sweeping epic", "hard science fiction", etc. I would enjoy books that are clearly not so more.
Long story short, is starts with a group of 1939 science fiction writers, one of which eventually has a huge success. On his dying bed, he leaves his entire fortune to a foundation with the purpose to invest and support space colonization, in particular other star systems. Somehow, this seed money manages to successfully fund the construction of a beam sail starship which ends up putting people on another star's planet. Most of the book is the story of the family descendants who "live the dream" by monitoring the long journey of the automated ship.
First of all, I didn't enjoy the writing style. Episodic and descriptive, it felt more appropriate for a history book or a diary than a science fiction novel. Then the biases of the writer are more than made evident when he belittles antiscience protesters and religious colonists that believe in the starship as their god. It's not that I don't agree with him, but it was written so condescendingly that it bothered me. Same with the "I told you so" part with the asteroid on collision course with Earth. Same when the Arkwright descendants are pretty much strongarmed into getting into the family business. And third, while focusing on the Arkwright clan, the book completely ignored the rest of the world. While explaining how they designed and constructed and monitored a starship for generations, the author ignored any scientific breakthroughs that happened during that time. It is like the only people that cared about science and space expansion were the Arkwrights. It made the book feel very provincial. I would have preferred to see them in a global context, rather than read about their family issues.
I liked the sentiment, though. The idea that if you put your mind to something, you can do it. Of course, ignoring economic, technical and probabilistic realities does help when you write the book, but still. The story is centered on an old science fiction writer who takes humanity to another star, clearly something the author would have liked to have been autobiographical. It felt like one of those stories grandpas tell their children, all moral and wise, yet totally boring. It's not that they don't mean well and that the moral isn't good, but the way they tell it makes it unappetizing to small children. If I had to use one word to describe this book it is unappetizing
Funny thing is that I've read a similar centuries spanning book about the evolution of mankind that I liked a lot more and was much better written. I would suggest you don't read Arkwright and instead try Accelerando, by Charles Stross.
It is about time to revisit my series on ASP.Net MVC Core. From the time of my last blog post the .Net Core version has changed to 1.1, so just installing the SDK and running the project was not going to work. This post explains how to upgrade a .Net project to the latest version.
Pressing the batch Update button for NuGet packages corrupted project.json. Here are the steps to successfully migrate a .Net Core project to a higher version.
Change the version of the SDK in global.json - you can find out the SDK version by creating a new .Net Core project and checking what it uses
Change "netcoreapp1.0" to "netcoreapp1.1" in project.json
Change Microsoft.NETCore.App version from "1.0.0" to "1.1.0" in project.json
Add
"runtimes": { "win10-x64": { } },
to project.json
Go to "Manage NuGet packages for the solution", to the Update tab, and update projects one by one. Do not press the batch Update button for selected packages
Some packages will restore, but remain in the list. Skip them for now
Whenever you see a "downgrade" warning when restoring, go to those packages and restore them next
For packages that tell you to upgrade NuGet, ignore them, it's an error that probably happens because you restore a package while the previous package restoring was not completed
For the remaining packages that just won't update, write down their names, uninstall them and reinstall them
That should do it. For detailed steps of what I actually did to get to this concise list, read on.
Long version
Step 0 - I don't care, just load the damn project!
Downloaded the source code from GitHub, loaded the .sln with Visual Studio 2015. Got a nice blocking alert, because this was a .NET Core virgin computer: Of course, I could have tried to install that version, but I wanted to upgrade to the latest Core.
If your application is referencing the .NET Core framework, your should update the references in your project.json file for netcoreapp1.0 or Microsoft.NetCore.App version 1.0 to version 1.1. In the default project.json file for an ASP.NET Core project running on the .NET Core framework, these two updates are located as follows:
Two places to update project.json to .NET Core 1.1
to be continued...
I got to the second step, but still got the alert...
Step 2 - fumble around
... so I commented out the sdk property in global.json. I got another alert:
This answer recommended uninstalling old versions of SDKs, in my case "Microsoft .NET Core 1.0.1 - SDK 1.0.0 Preview 2-003131 (x64)". Don't worry, it didn't work. More below:
TL;DR; version: do not uninstall the Visual Studio .NET Core Tooling
And then... got the same No executable found matching command "dotnet=projectmodel-server" error again.
I created a new .NET core project, just to see the version of SDK it uses: 1.0.0-preview2-003131 and I added it to global.json and reopened the project. It restored packages and didn't throw any errors! Dude, it even compiled and ran! But now I got a System.ArgumentException: The 'ClientId' option must be provided. Probably it had something to do with the Secret Manager. Follow the steps in the link to store your secrets in the app. It then worked.
Step 1.1 (see what I did there?) - continue to read the Microsoft documentation
The third step in the Microsoft instructions was removed by me because it caused some problems to me. So don't do it, yet. It was
Update your ASP.NET Core packages dependencies to use the new 1.1.0 versions. You can do this by navigating to the NuGet package manager window and inspecting the “Updates” tab for the list of packages that you can update.
Updating Packages using the NuGet package manager UI with the last pre-release build of ASP.NET Core 1.1
Since I had not upgraded the packages, as in the Microsoft third step, I decided to do it. 26 updates waited for me, so I optimistically selected them all and clicked Update. Of course, errors! One popped up as more interesting: Package 'Microsoft.Extensions.SecretManager.Tools 1.0.0' uses features that are not supported by the current version of NuGet. To upgrade NuGet, see http://docs.nuget.org/consume/installing-nuget. Another was even more worrisome: Unexpected end of content while loading JObject. Path 'dependencies', line 68, position 0 in project.json. Somehow the updating operation for the packages corrupted project.json! From a 3050 byte file, it now was 1617.
Step 3 - repair what the Microsoft instructions broke
Suspecting it was a problem with the NuGet package manager, I went to the link in the first error. But in Visual Studio 2015 NuGet is included and it was clearly the latest version. So the only solution was to go through each package and see which causes the problem. And I went to 26 packages and pressed Install on each and it worked. Apparently, the batch Update button is causing the issue. Weirdly enough there are two packages that were installed, but remained in the Update tab and also appeared in the Consolidate tab: BundleMinifier.Core and Microsoft.EntityFrameworkCore.Tools, although I can't to anything with them there.
Another package (Microsoft.VisualStudio.Web.CodeGeneration.Tools 1.0.0) caused another confusing error: Package 'Microsoft.VisualStudio.Web.CodeGeneration.Tools 1.0.0' uses features that are not supported by the current version of NuGet. To upgrade NuGet, see http://docs.nuget.org/consume/installing-nuget. Yet restarting Visual Studio led to the disappearance of the CodeGeneration.Tools error.
So I tried to build the project only to be met with yet another project.json corruption error: Can not find runtime target for framework '.NETCoreAPP, Version=v1.0' compatible with one of the target runtimes: 'win10-x64, win81-x64, win8-x64, win7-x64'. Possible causes: [blah blah] The project does not list one of 'win10-x64, win81-x64, win7-x64' in the 'runtimes' [blah blah]. I found the fix here, which was to add
As you probably know, whenever I blog something, an automated process sends a post to Facebook and one to Twitter. As a result, some people comment on the blog, some on Facebook or Twitter, but more often someone "likes" my blog post. Don't get me wrong, I appreciate the sentiment, but it is quite meaningless. Why did you like it? Was it well written, well researched, did you find it useful and if so in what way? I would wager that most of the time the feeling is not really that clear cut, either. Maybe you liked most of the article, but then you absolutely hated a paragraph. What should you do then? Like it a bunch of times and hate it once?
This idea that people should express emotion related to someone else's content is not only really really stupid, it is damaging. Why? I am glad you asked - clearly you already understand the gist of my article and have decided to express your desire for knowledge over some inevitable sense of awe and gratitude. Because if it is natural for people to express their emotions related to your work, then that means you have to accept some responsibility for what they get to feel, and then you fall into the political correctness, safe zone, don't do anything for someone might get hurt pile of shit. Instead, accept the fact that sharing knowledge or even expressing an opinion is nothing more than a data signal that people may or may not use. Don't even get me started on that "why didn't you like my post? was it something wrong with it? Are you angry with me?" insecurity bullshit that may be cute coming from a 12 year old, but it's really creepy with 50 year old people.
Back to my amazing blog posts, I am really glad you like them. You make my day. I am glowing and I am filled with a sense of happiness that is almost impossible to describe. And then I start to think, and it all goes away. Why did you like it, I wonder? Is it because you feel obligated to like stuff when your friends post? Is it some kind of mercy like? Or did you really enjoy part of the post? Which one was it? Maybe I should reread it and see if I missed something. Mystery like! Nay, more! It is a riddle, wrapped in a mystery, inside an enigma; but perhaps there is a key. That key is personal interest in providing me with useful feedback, the only way you can actually help me improve content.
Let me reiterate this as clear as I possibly can: the worse thing you can do is try to spare my feelings. First of all, it is hubris to believe you have any influence on them at all. Second, you are not skilled enough to understand in what direction your actions would influence them anyway. And third, feeling is the stuff that fixates memories, but you have to have some memory to fixate first! Don't sell a lifetime of knowing something on a few seconds of feeling gratified by some little smiley or bloody heart.
And then there is another reason, maybe one that is more important than everything I have written here. When you make the effort of summarizing what you have read in order to express an opinion you retrieve and generate knowledge in your own head, meaning you will remember it better and it will be more useful to you.
So fuck your wonderful emotions! Give me your thoughts and knowledge instead.
Ever wanted to write a quick and dirty Javascript function that would get content from the web and do something with it, but you couldn't because of the pesky cross origin security limitations? Good Samaritans have created CORS proxies to help with that!
One of them is crossorigin.me, a completely free (and open source) proxy which can be used very easily. Instead of doing an AJAX request to http://someDomainYouDontOwn/somePage, you do it to https://crossorigin.me/http://someDomainYouDontOwn/somePage. And it works for any GET requests, as long as the Origin header is sent (browsers set it automatically for Ajax calls, but not for regular browser requests, so that why https://crossorigin.me/https://google.com will show Origin: header is required if you open it with a browser).
But there are other options, too. CORS Anywhere, CORS proxy and even using YQL are all valid, and that after just five minutes of googling around.
Of course, one might not want to depend on flimsy external free services for a production app, but it sounds perfect for the quick and dirty bastards like me.
I want to let you know about the latest features implemented in Bookmark Explorer.
The version number for the extension is already 2.9.3, quickly approaching the new rewrite I am planning for 3.0.0, yet every time I think I don't have anything else I could add, I find new ideas. It would be great if the users of the extension would give me more feedback about the features they use, don't use or want to have.
Here are some examples of new features:
Skip button - moves the current page to the end of the bookmark folder and navigates to the next link. Useful for those long articles that you don't have the energy to read, but you want to.
Custom URL comparison scheme. Useful for those sites where pages with different parameters or hash values are considered different and you get duplicate notification warnings for no good reason.
Duplicate remover in the Manage page. This is an older feature, but now the button for it only appears where there are duplicates in the folder and with the custom URL scheme it's much more useful.
Option to move selected bookmarks to start or end of folder, something that is cumbersome to do in the Chrome Bookmark Manager
Automatically cleaning bookmark URLs of marketing parameters. This is in the Advanced settings section and must be enabled manually. So far it removes utm_*, wkey, wemail, _hsenc, _hsmi and hsCtaTracking, but I plan to remove much more, like those horrible hashes from Medium, for example. Please let me know of particular URL patterns you want to clean in your bookmarks and if perhaps you want the cleaning to be done automatically for all open URLs
As always, if you want to install the extension go to its Google Chrome extension page: Siderite's Bookmark Explorer
I have switched to a new project at work and it surprised me with the use of a programming language called Haxe. I have just begun, so I will not be able to explain to you all its intricacies, but I am probably going to write some more blog posts about it as I tread along.
What is interesting about Haxe is that it was not designed as just a language, but as a cross platform toolkit, meaning that when you compile the code you've created, it generates code in other languages and platforms, be it C++, C#, Java, Javascript, Flash, PHP, Lua, Java, Python, etc on Windows, iOS, Linux, Android and so on. It's already version 3, so you probably did hear of it, it was just me that was ignorant. Anyway, let's explore a little bit what Haxe can do.
Installing
The starting guide from their web site is telling us to follow some steps, but the gist of it is this:
Download and install an IDE - we'll use FlashDevelop for this intro, for no other reason than this is what I use at work (and it's free)
Once it starts, it will start AppMan, which lets you choose what to install
Select Haxe+Neko
Select Standalone debug Flash Player
Select OpenFL Installer Script
Click Install 3 Items
Read the starting guide for more details.
Writing Code
In FlashDevelop, go to Project → New Project and select OpenFL Project. Let's call it - how else? - HaxeHelloWorld. Note that right under the menu, in the toolbar, you have two dropdowns, one for Debug/Release and another for the target. Let's choose Debug and neko and run it. It should show you an application with a black background, which is the result of running the generated .exe file (on Windows) "HaxeHelloWorld\bin\windows\neko\debug\bin"\HaxeHelloWorld.exe".
Let's write something. The code should look like this, to which you add the part written in italics:
package;
import openfl.display.Sprite; import openfl.Lib; /** * ... * @author Siderite */ class Main extends Sprite {
public function new() { super();
var stage = flash.Lib.current.stage; var text = new flash.text.TextField(); text.textColor = 0xFFFFFF; text.text = "Hello world!"; stage.addChild(text);
} }
Run it and it should show a "Hello world!" message, white on black. Now let's play with the target. Switch it to Flash, html5, neko, windows and run it.
They all show more or less the same white text on a black background. Let's see what it generates:
In HaxeHelloWorld\bin\flash\debug\bin\ there is now a file called HaxeHelloWorld.swf.
In HaxeHelloWorld\bin\html5\debug\bin\ there is now a web site containing index.html, HaxeHelloWorld.js, HaxeHelloWorld.js.map,favicon.png,lib\howler.min.js and lib\pako.min.js. It's a huge thing for a hello world and it is clearly a machine generated code. What is interesting, though, is that it uses a canvas to draw the string
In HaxeHelloWorld\bin\windows\neko\debug\bin\ there are several files, HaxeHelloWorld.exe and lime.ndll being the relevant ones. In fact, lime.ndll is not relevant at all, since you can delete it and the program still works, but if you remove Neko from your system, it will crash with an error saying neko.dll is missing, so it's not a real Windows executable.
Now it gets interesting: in D:\_Projects\HaxeHelloWorld\bin\windows\cpp\debug\bin\ you have another HaxeHelloWorld.exe file, but this time it works directly. And if you check D:\_Projects\HaxeHelloWorld\bin\windows\cpp\debug\obj\ you will see generated C++: .cpp and .h files
How about C#? Unfortunately, it seems that the only page explaining how to do this is on the "old.haxe.org" domain, here: Targeting the C# Platform. It didn't work with this code, instead I made it work with the simpler hello world code in the article. Needless to say, the C# code is just as readable as the Javascript above, but it worked!
What I think of it
As far as I will be working with the language, I will be posting stuff I learn. For example, it is obvious FlashDevelop borrowed a lot from Visual Studio, and Haxe a lot from C#, however the familiarity with those might confuse you when Haxe does weird stuff like not having break instructions in switch blocks or not having the protected or internal access modifiers, yet having inheriting classes able to access private members of their base class.
What now?
Well, at the very least, you can try this free to play and open source programming toolkit to build applications that are truly cross platform. Not everything will be easy, but Haxe seems to have built a solid code base, with documentation that is well done and a large user base. It is not the new C# (that's D#, obviously), but it might be interesting to be familiar with it.
I was thinking about what to discuss about computers next and I realized that I hardly ever read anything about the flow of an application. I mean, sure, when you learn to code the first thing you hear is that a program is like a set of instructions, not unlike a cooking recipe or instructions from a wife to her hapless husband when she's sending him to the market. You know, stuff like "go to the market and buy 10 eggs. No, make it 20. If they don't have eggs get salami." Of course, her software developer husband returns with 20 salamis "They didn't have eggs", he reasons. Yet a program is increasingly not a simple set of instructions neatly following each other.
So I wrote like a 5 page treatise on program control flow, mentioning Turing and the Benedict Cumberbatch movie, child labor and farm work, asking if it is possible to turn any program, with its parallelism and entire event driven complexity to a Turing machine for better debugging. It was boring, so I removed it all. Instead, I will talk about conditional statements and how to refactor them, when it is needed.
A conditional statement is one of the basic statements of programming, it is a decision that affects what the program will execute next. And we love telling computers what to do, right? Anyway, here are some ways if/then/else or switch statements are used, some bad, some good, and how to fix whatever problems we find.
Team Arrow
First of all, the arrow antipattern. It's when you have if blocks in if blocks until your code looks like an arrow pointing right:
if (data.isValid()) { if (data.items&&data.items.length) { var item=data.items[0]; if (item) { if (item.isActive()) { console.log('Oh, great. An active item. hurray.'); } else { throw"Item not active! Fatal terror!"; } } } }
This can simply be avoided by putting all the code in a method and inverting the if branches, like this:
if (!data.isValid()) return; if (!data.items||!data.items.length) return; var item=data.items[0]; if (!item) return; if (!item.isActive()) { throw"Item not active! Fatal terror!"; } console.log('Oh, great. An active item. hurray.');
See? No more arrow. And the debugging is so much easier.
There is a sister pattern of The Arrow called Speedy. OK, that's a Green Arrow joke, I have no idea how it is called, but basically, since a bunch of imbricated if blocks can be translated into a single if with a lot of conditions, the same code might have looked like this:
if (data.isValid()&&data.items&&data.items.length&&data.items[0]) { var item=data.items[0]; if (!item.isActive()) { throw"Item not active! Fatal terror!"; } console.log('Oh, great. An active item. hurray.'); }
While this doesn't look like an arrow, it is in no way a better code. In fact it is worse, since the person debugging this will have to manually check each condition to see which one failed when a bug occurred. Just remember that if it doesn't look like an arrow, just its shaft, that's worse. OK, so now I named it: The Shaft antipattern. You first heard it here!
There is also a cousin of these two pesky antipatterns, let's call it Black Shaft! OK, no more naming. Just take a look at this:
if (person&&person.department&&person.department.manager&&person.department.manager.phoneNumber) { call(person.department.manager.phoneNumber); }
I can already hear a purist shouting at their monitor something like "That's because of the irresponsible use of null values in all programming languages!". Well, null is here to stay, so deal with it. The other problem is that you often don't see a better solution to something like this. You have a hierarchy of objects and any of them might be null and you are not in a position where you would cede control to another piece of code based on which object you refer to. I mean, one could refactor things like this:
if (person) { person.callDepartmentManager(); } ... function callDepartmentManager() { if (this.department) { this.department.callManager(); } }
, which would certainly solve things, but adds a lot of extra code. In C# 6 you can do this:
var phoneNumber = person?.department?.manager?.phoneNumber; if (phoneNumber) { call(phoneNumber); }
This is great for .NET developers, but it also shows that rather than convince people to use better code practices, Microsoft decided this is a common enough problem it needed to be addressed through features in the programming language itself.
To be fair, I don't have a generic solution for this. Just be careful to use this only when you actually need it and handle any null values with grace, rather than just ignore them. Perhaps it is not the best place to call the manager in a piece of code that only has a reference to a person. Perhaps a person that doesn't seem to be in any department is a bigger problem than the fact you can't find their manager's phone number.
The Omnipresent Switch
Another smelly code example is the omnipresent switch. You see code like this:
switch(type) { case Types.person: walk(); break; case Types.car: run(); break; case Types.plane: fly(); break; }
This isn't so bad, unless it appears in a lot of places in your code. If that type variable is checked again and again and again to see which way the program should behave, then you probably can apply the Replace Conditional with Polymorphism refactoring method.
Or, in simple English, group all the code per type, then only decide in one place which of them you want to execute. Polymorphism might work, but also some careful rearranging of your code. If you think of your code like you would a story, then this is the equivalent of the annoying "meanwhile, at the Bat Cave" switch. No, I want to see what happens at the Beaver's Bend, don't fucking jump to another unrelated segment! Just try to mentally filter all switch statements and replace them with a comic book bubble written in violently zigzagging font: "Meanwhile...".
A similar thing is when you have a bool or enum parameter in a method, completely changing the behavior of that method. Maybe you should use two different methods. I mean, stuff like:
function doWork(iFeelLikeIt) { if (iFeelLikeIt) { work(); } else { fuckIt(); } }
happens every day in life, no need to see it in code.
Optimizing in the wrong place
Let's take a more serious example:
function stats(arr,method) { if (!arr||!arr.length) return; arr.sort(); switch (method) { case Methods.min: return arr[0]; case Methods.max: return arr[arr.length-1]; case Methods.median: if (arr.length%2==0) { return (arr[arr.length/2-1]+arr[arr.length/2])/2; } else { return arr[Math.ceiling(arr.length/2)]; } case Methods.mode: var counts={}; var max=-1; var result=-1; arr.forEach(function(v) { var count=(counts[v]||0)+1; if (count>max) { result=v; max=count; } counts[v]=count; }); return result; case Methods.average: var sum=0; arr.forEach(function(v) { sum+=v; }); return sum/arr.length; } }
OK, it's still a silly example, but relatively less silly. It computes various statistical formulas from an array of values. At first, it seems like a good idea. You sort the array that works for three out of five methods, then you write the code for each, which is greatly simplified by working with a sorted array. Yet for the last two, being sorted does nothing and both of them have loops through the array. Sorting the array would definitely loop through the array as well. So, let's move the decision earlier:
function min(arr) { if (!arr||!arr.length) return; return Math.min.apply(null,arr); }
function max(arr) { if (!arr||!arr.length) return; return Math.max.apply(null,arr); }
function median(arr) { if (!arr||!arr.length) return; arr.sort(); var half=Math.ceiling(arr.length/2); if (arr.length%2==0) { return (arr[half-1]+arr[half])/2; } else { return arr[half]; } }
function mode(arr) { if (!arr||!arr.length) return; var counts={}; var max=-1; var result=-1; arr.forEach(function(v) { var count=(counts[v]||0)+1; if (count>max) { result=v; max=count; } counts[v]=count; }); return result; }
function average(arr) { if (!arr||!arr.length) return; return arr.reduce(function (p, c) { return p + c; }) / arr.length; }
As you can see, I only use sorting in the median function - and it can be argued that I could do it better without sorting. The names of the functions now reflect their functionalities. The min and max functions take advantage of the native min/max functions of Javascript and other than the check for a valid array, they are one liners. More than this, it was natural to use various ways to organize my code for each method; it would have felt weird, at least for me, to use forEach and reduce and sort and for loops in the same method, even if each was in its own switch case block. Moreover, now I can find the min, max, mode or median of an array of strings, for example, while an average would make no sense, or I can refactor each function as I see fit, without caring about the functionality of the others.
Yet, you smugly point out, each method uses the same code to check for the validity of the array. Didn't you preach about DRY a blog post ago? True. One might turn that into a function, so that there is only one point of change. That's fair. I concede the point. However don't make the mistake of confusing repeating a need with repeating code. In each of the functions there is a need to check for the validity of the input data. Repeating the code for it is not only good, it's required. But good catch, reader! I wouldn't have thought about it myself.
But, you might argue, the original function was called stats. What if a manager comes and says he wants a function that calculates all statistical values for an array? Then the initial sort might make sense, but the switch doesn't. Instead, this might lead to another antipattern: using a complex function only for a small part of its execution. Something like this:
var stats=getStats(arr); var middle=(stats.min+stats.max)/2;
In this case, we only need the minimum and maximum of an array in order to get the "middle" value, and the code looks very elegant, yet in the background it computes all the five values, a waste of resources. Is this more readable? Yes. And in some cases it is preferred to do it like that when you don't care about performance. So this is both a pattern and an antipattern, depending on what is more important to your application. It is possible (and even often encountered) to optimize too much.
The X-ifs
A mutant form of the if statement is the ternary operator. My personal preference is to use it whenever a single condition determines one value or another. I prefer if/then/else statements to actual code execution. So I like this:
function boolToNumber(b) { return b?1:0; }
function exec(arr) { if (arr.length%2==0) { split(arr,arr.length/2); } else { arr.push(newValue()); } }
but I don't approve of this:
function exec(arr) { arr.length%2 ? arr.push(newValue()) : split(arr,arr.length/2); }
var a; if (x==1) { a=2; } else { a=6; }
var a=x==1 ? 2 : (y==2?5:6);
The idea is that the code needs to be readable, so I prefer to read it like this. It is not a "principle" to write code as above - as I said it's a personal preference, but do think of the other people trying to make heads and tails of what you wrote.
We are many, you are but one
There is a class of multiple decision flow that is hard to immediately refactor. I've talked about if statements that do the entire work in one of their blocks and of switch statements that can be easily split into methods. However there is the case where you want to do things based on the values of multiple variables, something like this:
if (x==1) { if (y==1) { console.log('bottom-right'); } else { console.log('top-right'); } } else { if (y==1) { console.log('bottom-left'); } else { console.log('top-left'); } }
There are several ways of handling this. One is to, again, try to move the decision on a higher level. Example:
if (x==1) { logRight(y); } else { logLeft(y); }
Of course, this particular case can be fixed through computation, like this:
var h=y==1?'right':'left'; var v=x==1?'bottom':'top'; console.log(v+'-'+h);
Assuming it was not so simple, though, we can choose to reduce the choice to a single decision:
Another more complicated issue regarding conditional statements is when they are not actually encoding a decision, but testing for a change. Something like:
if (current!=prev) { clearData(); var data=computeData(current); setData(data); prev=current; }
This is a perfectly valid piece of code and in many situations is what is required. However, one must pay attention to the place where the decision gets taken as compared with the place the value changed. Isn't that more like an event handler, something that should be designed differently, architecture wise? Why keep a previous value and react to the change only when I get into this piece of code and not react to the change of the value immediately? Fire an event that the value is changed and subscribe to the event via a piece of code that refreshes the data. One giveaway for this is that in the code above there is no actual use of the prev value other than to compare it and set it.
Generalizations
As a general rule, try to take the decisions that are codified by if and switch statements as early as possible. The code must be readable to humans, sometimes in detriment of performance, if it is not essential to the functionality of your program. Avoid decision statements within other decision statements (arrow ifs, ternary operator in a ternary operator, imbricated switch and if statements). Split large pieces of code into small, easy to understand and properly named, methods (essentially creating a lower level than your conditional statement, thus relatively taking it higher in the code hierarchy).
What's next
I know this is a lower level programming blog post, but not everyone reading my blog is a senior dev - I mean, I hope so, I don't want to sound completely stupid. I am planning some new stuff, related to my new work project, but it might take some time until I understand it myself. Meanwhile, I am running out of ideas for my 100 days of writing about code challenge, so suggestions are welcome. And thank you for reading so far :)
I want to talk today about principles of software engineering. Just like design patterns, they range from useful to YAA (Yet Another Acronym). Usually, there is some guy or group of people who decide that a set of simple ideas might help software developers write better code. This is great! Unfortunately, they immediately feel the need to assign them to mnemonic acronyms that make you wonder if they didn't miss some principles from their sets because they were bad at anagrams.
Some are very simple and not worth exploring too much. DRY comes from Don't Repeat Yourself, which basically means don't write the same stuff in multiple places, or you will have to keep them synchronized at every change. Simply don't repeat yourself. Don't repeat yourself. See, it's at least annoying. KISS comes from Keep It Simple, Silly - yeah, let's be civil about it - anyway, the last letter is there just so that the acronym is actually a word. The principle states that avoiding unnecessary complexity will make your system more robust. A similar principle is YAGNI (You Aren't Gonna Need It - very New Yorkish sounding), which also frowns upon complexity, in particular the kind you introduce in order to solve a possible future problem that you don't have.
But what I wanted to talk about was SOLID, which is so cool that not only does it sound like something you might want your software project to be, but it's a meta acronym, each letter coming from another acronym:
S - SRP
O - OCP
L - LSP
I - ISP
D - DIP
OK, I was just making it look harder than it actually is. Each of the (sub)acronyms stands for a principle (hence the last P in each) and even if they have suspiciously sounding names that hint on how much someone wanted to call their principles SOLID, they are really... err... solid. They refer specifically to object oriented programming, but I am sure they apply to all types. Let's take a look:
The idea is that each of your classes (or modules, units of code, functions, etc) should strive towards only one functionality. Why? Because if you want to change your code you should first have a good reason, then you should know where is that single (DRY) point where that reason applies. One responsibility equals one and only one reason to change.
Short example:
function getTeam() { var result=[]; var strongest=null; this.fighters.forEach(function(fighter) { result.push(fighter.name); if (!strongest||strongest.power<fighter.power) { strongest=fighter; } }); return { team:result, strongest:strongest; }; }
This code iterates through the list of fighters and returns a list of their names. It also finds the strongest fighter and returns that as well. Obviously, it does two different things and you might want to change the code to have two functions that each do only one. But, you will say, this is more efficient! You iterate once and you get two things for the price of one! Fair enough, but let's see what the disadvantages are:
You need to know the exact format of the return object - that's not a big deal, but wouldn't you expect to have a team object returned by a getTeam function?
Sometimes you might want just the list of fighters, so computing the strongest is superfluous. Similarly, you might only want the strongest player.
In order to add stuff in the iteration loop, the code has become more complex - at least when reading it - than it has to be.
Here is how the code could - and should - have looked. First we split it into two functions:
function getTeam() { var result=[]; this.fighters.forEach(function(fighter) { result.push(fighter.name); }); return result; }
function getStrongestFighter() { var strongest=null; this.fighters.forEach(function(fighter) { if (!strongest||strongest.power<fighter.power) { strongest=fighter; } }); return strongest; }
Then we refactor it to something simple and readable:
function getTeam() { returnthis.fighters .map(function(fighter) { return fighter.name; }); }
function getStrongestFighter() { returnthis.fighters .reduce(function(strongest,val) { return !strongest||strongest.power<val.power?val:strongest; }); }
When you write your code the last thing you want to do is go back to it and change it again and again whenever you implement a new functionality. You want the old code to work, be tested to work, and allow new functionality to be built on top of it. In object oriented programming that simply means you can extend classes, but practically it also means the entire plumbing necessary to make this work seamlessly. Simple example:
OK, this is a silly example, since I am lazily emulating inheritance in a prototype based language such as Javascript. But the result is the same: both constructors will .fight by default, but each of them will have different implementations. Note that while I cannibalized bits of Fighter to build ProfessionalFighter, I didn't have to change it at all. I also built a factory method that returns different objects based on the input. Both possible returns will have a .fight method.
The open/closed principle also applies to non inheritance based languages and even in classic OOP languages. I believe it leads to a natural outcome: preferring composition over inheritance. Write your code so that the various modules just seamlessly connect to each other, like Lego blocks, to build your end product.
No, L is not coming from any word that they could think of, so they dragged poor Liskov into it. Forget the definition, it's really stupid and complicated. Not KISSy at all! Assume you have the base class Fighter and the more specialized subclass ProfessionalFighter. If you had a piece of code that uses a Fighter object, then this principle says you should be able to replace it with a ProfessionalFighter and the piece of code would still be correct. It may not be what you want, but it would work.
But when does a subclass break this principle? One very ugly antipattern that I have seen is when general types know about their subtypes. Code like "if I am a professional fighter, then I do this" breaks almost all SOLID principles and it is stupid. Another case is when the general class has everything they can think of, either abstract or implemented as empty or throwing an error, then the base classes implement one or the other of the functions. Dude! If your fighter doesn't implement .fight, then it is not a fighter!
I don't want to add code to this, since the principle is simple enough. However, even if it is an idea that primarily applies to OOP it doesn't mean it doesn't have its uses in other types of programming languages. One might say it is not even related to programming languages, but to concepts. It basically says that an orange should behave like an orange if it's blue, otherwise don't call it a blue orange!
This one is simple. It basically is the reverse of the Liskov: split your interfaces - meaning the desired functionality of your code - into pieces that are fully used. If you have a piece of code that uses a ProfessionalFighter, but all it does is use the .fight method, then use a Fighter, instead. Silly example:
class Program { publicstaticvoid Main() { EnglishFighter f=getMeAFighter(); f.Fight(); } }
I don't even know if it's valid code, but anyway, the idea here is that there is no reason for me to declare and use the variable f as an EnglishFighter, if all it does is fight. Use a Fighter type. And a YAGNI on you if you thought "wait, but what if I want him to talk later on?".
Oh, this is a nice one! But it doesn't live in a vacuum. It is related to both SRP and OCP as it states that high level modules should not depend on low level modules, only on their abstractions. In other words, use interfaces instead of implementations wherever possible.
I wrote an entire other post about Inversion of Control, the technique that allows you to properly use and enjoy interfaces, while keeping your modules independent, so I am not going to repeat things here. As a hint, simply replacing Fighter f=new Fighter() with IFighter f=new Fighter() is not enough. You must use a piece of code that decides for you what implementation of an interface will be used, something like IFighter f=GetMeA(typeof(IFighter)).
The principle is related to SRP because it says a boss should not be controlling or depending on what particular things the employees will do. Instead, he should just hire some trustworthy people and let them do their job. If a task depends so much on John that you can't ever fire him, you're in trouble. It is also related to OCP because the boss will behave like a boss no matter what employee changes occur. He may hire more people, replace some, fire some others, the boss does not change. Nor does he accept any responsibility, but that's a whole other principle ;)
Conclusions
I've explored some of the more common acronyms from hell related to software development and stuck more to SOLID, because ... well, you have to admit, calling it SOLID works! Seriously now, following principles such as these (choose your own, based on your own expertise and coding style) will help you a lot later on, when the complexity of your code will explode. In a company there is always that one poor guy who knows everything and can't work well because everybody else is asking him why and how something is like it is. If the code is properly separated on solid principles, you just need to look at it and understand what it does and keep the efficiency of your changes high. One small change for man , like. Let that unsung hero write their code and reach software Valhalla.
SRP keeps modules separated, OCP keeps code free of need for modifications, LSP and ISP make you use the basest of classes or interfaces, reinforcing the separation of modules, while DIP is helping you sharpen the boundaries between modules. Taken together, SOLID principles are obviously about focus, allowing you to work on small, manageable parts of the code without needing knowledge of others or having to make changes to them.
C# started up with the IEnumerable interface, which exposed one method called GetEnumerator. This method would return a specialized object (implementing IEnumerator) that could give you from a collection of items the current item and could also advance. Unlike Java on which C# is originally based, this interface was inherited by even the basest of collection objects, like arrays. This allowed a special construct in the language: foreach. One uses it very simply:
for (var item in ienumerable) // do something
. No need to know how or from where the item is exactly retrieved from the collection, just get the first, then the next and so on until there are no more items.
In .NET 2.0 generics came, along their own interfaces like IEnumerable<T>, holding items of a specific type, but the logic is the same. It also introduced another language element called yield. One didn't need to write an IEnumerator implementation anymore, they could just define a method that returned an IEnumerable and inside "yield return" values. Something like this:
publicclass Program { publicstaticvoid Main(string[] args) { var enumerator = Fibonacci().GetEnumerator(); for (var i = 0; enumerator.MoveNext() && i < 10; i++) { var v = enumerator.Current; Console.WriteLine(v); } Console.ReadKey(); }
publicstatic IEnumerable<int> Fibonacci() { var i1 = 0; var i2 = 1; while (true) { yield return i2; i2 += i1; i1 = i2 - i1; } } }
This looks a bit weird. A method is running a while(true) loop with no breaks. Shouldn't it block the execution of the program? No, because of the yield construct. While the Fibonacci series is infinite, we would only get the first 10 values. You can also see how the enumerator works, when used explicitly.
Iterators and generators in Javascript ES6
EcmaScript version 6 (or ES6 or ES2015) introduced the same concepts in Javascript. An iterator is just an object that has a next() method, returning an object containing the value and done properties. If done is true, value is disregarded and the iteration stops, if not, value holds the current value. An iterable object will have a method that returns an iterator, the method's name being Symbol.iterator. The for...of construct of the language iterates the iterable. String, Array, TypedArray, Map and Set are all built-in iterables, because the prototype objects of them all have a Symbol.iterator method. Example:
var iterable=[1,2,3,4,5]; for (v of iterable) { console.log(v); }
But what about generating values? Well, let's do it using the knowledge we already have:
var iterator={ i1:0, i2:1, next:function() { var result = { value: this.i2 } this.i2+=this.i1; this.i1=this.i2-this.i1; return result; } };
var iterable = {}; iterable[Symbol.iterator]=() => iterator;
var iterator=iterable[Symbol.iterator](); for (var i=0; i<10; i++) { var v=iterator.next(); console.log(v.value); }
As you can see, it is the equivalent of the Fibonacci code written in C#, but look at how unwieldy it is. Enter generators, a feature that allows, just like in C#, to define functions that generate values and the iterable associated with them:
function* Fibonacci() { var i1=0; var i2=1; while(true) { yield i2; i2+=i1; i1=i2-i1; } }
var iterable=Fibonacci();
var iterator=iterable[Symbol.iterator](); for (var i=0; i<10; i++) { var v=iterator.next(); console.log(v.value); }
No, that's not a C pointer, thank The Architect, it's the way Javascript ES6 defines generators. Same code, much clearer, very similar to the C# version.
Uses
OK, so these are great for mathematics enthusiasts, but what are we, regular dudes, going to do with iterators and generators? I mean, for better or for worse we already have for and .forEach in Javascript, what do we need for..of for? (pardon the pun) And what do generators help with?
Well, in truth, one could get away simply without for..of. The only object where .forEach works differently is the Map object, where it returns only the values, as different from for..of which returns arrays of [key,value]. However, considering generators are new, I would expect using for..of with them to be more clear in code and more inline with what foreach does in C#.
Generators have the ability to easily define series that may be infinite or of items which are expensive resources to get. Imagine a download of a large file where each chunk is a generated item. An interesting use scenario is when the .next function is used with parameters. This is Javascript, so an iterator having a .next method only means it has to be named like that. You can pass an arbitrary number of parameters. So here it is, a generator that not only dumbly spews out values, but also takes inputs in order to do so.
In order to thoroughly explore the value of iterators and generators I will use my extensive knowledge in googling the Internet and present you with this very nice article: The Hidden Power of ES6 Generators: Observable Async Flow Control which touches on many other concepts like async/await (oh, yeah, that should be another interesting C# steal), observables and others that are beyond the scope of this article.
I hope you liked this short intro into these interesting new features in ES6.
Can you tell me what is the difference between these to pieces of code?
var f=function() { alert('f u!'); }
function f() { alert('f u!'); }
It's only one I can think of and with good code hygiene it is one that should never matter. It is related to 'hoisting', or the idea that in Javascript a variable declaration is hoisted to the top of the function or scope before execution. In other words, I can see there is a function f before the declarations above. And now the difference: 'var f = function' will have its declaration hoisted, but not its definition. f will exist at the beginning of the scope, but it will be undefined; the 'function f' format will have both declaration and definition hoisted, so that at the beginning of the scope you will have available the function for execution.
I am not the authoritative person to go to for Javascript Promises, but I've used them extensively (pardon the pun) in Bookmark Explorer, my Chrome extension. In short, they are a way to handle methods that return asynchronously or that for whatever reason need to be chained. There are other ways to do that, for example using Reactive Extensions, which are newer and in my opinion better, but Rx's scope is larger and that is another story altogether.
Learning by examples
Let's take a classic and very used example: AJAX calls. The Javascript could look like this:
function get(url, success, error) { var xhttp = new XMLHttpRequest(); xhttp.onreadystatechange = function () { if (this.readyState == 4) { if (this.status == 200) { success(this.response); } else { error(this.status); } } }; xhttp.open("GET", url, true); xhttp.send(); }
get('/users',function(users) { //do something with user data },function(status) { alert('error getting users: '+status); })
It's a stupid example and not by far complete, but it shows a way to encapsulate an AJAX call into a function that receives an URL, a handler for success and one for error. Now let's complicate things a bit. I want to get the users, then for each active user I want to get the document list, then return the ones that contain a string. For simplicity's sake, let's assume I have methods that do all that and receive a success and an error handler:
var search = 'some text'; var result = []; getUsers(function (users) { users .filter(function (user) { return user.isActive(); }) .forEach(function (user) { getDocuments(user, function (documents) { result = result.concat(documents.filter(function (doc) { return doc.text.includes(text); })); }, function (error) { alert('Error getting documents for user ' + user + ': ' + error); }); }); }, function (error) { alert('Error getting users: ' + error); });
It's already looking wonky. Ignore the arrow anti pattern, there are worse issues. One is that you never know when the result is complete. Each call for user documents takes an indeterminate amount of time. This async programming is killing us, isn't it? We would have much better liked to do something like this instead:
var result = []; var search = 'some text'; var users = getUsers(); users .filter(function (user) { return user.isActive(); }) .forEach(function (user) { var documents = getDocuments(user); result = result.concat(documents.filter(function (doc) { return doc.text.includes(text); }));
});
First of all, no async, everything is deterministic and if the function for getting users or documents fails, well, it can handle itself. When this piece of code ends, the result variable holds all information you wanted. But it would have been slow, linear and simply impossible in Javascript, which doesn't even have a Pause/Sleep option to wait for stuff.
Now I will write the same code with methods that use Promises, then proceed on explaining how that would work.
var result = []; var search = 'some text'; var userPromise = getUsers(); userPromise.then(function (users) { var documentPromises = users .filter(function (user) { return user.isActive(); }) .map(function (user) { return getDocuments(user); }); var documentPromise = Promise.all(documentPromises); documentPromise .then(function (documentsArray) { documentsArray.forEach(function (documents) { result = result.concat(documents.filter(function (doc) { return doc.text.includes(search); }); }); // here the result is complete }) .catch (function (reason) { alert('Error getting documents:' + reason); }); });
Looks more complicated, but that's mostly because I added some extra variables for clarity.
The first thing to note is that the format of the functions doesn't look like the async callback version, but like the synchronous version: var userPromise=getUsers();. It doesn't return users, though, it returns the promise of users. It's like a politician function. This Promise object encapsulates the responsibility of announcing when the result is actually available (the .then(function) method) or when the operation failed (the .catch(function) method). Now you can pass that object around and still use its result (successful or not) when available at whatever level of the code you want it.
At the end I used Promise.all which handles all that uncertainty we were annoyed about. Not only does it publish an array of all the document getting operations, but the order of the items in the array is the same as the order of the original promises array, regardless of the time it took to execute any of them. Even more, if any of the operations fails, this aggregate Promise will immediately exit with the failure reason.
To exemplify the advantages of using such a pattern, let's assume that getting the users sometimes fails due to network errors. The Internet is not the best in the world where the user of the program may be, so you want to not fail immediately, instead retry the operation a few times before you do. Here is how a getUsersWithRetry would look:
function getUserWithRetry(times, spacing) { var promise = new Promise(function (resolve, reject) { var f = function () { getUsers() .then(resolve) .catch (function (reason) { if (times <= 0) { reject(reason); } else { times--; setTimeout(f, spacing); } }); } f(); }); return promise; }
What happens here? First of all, like all the get* methods we used so far, we need to return a Promise object. To construct one we give it as a parameter a function that receives two other functions: resolve and reject. Resolve will be used when we have the value, reject will be used when we fail getting it. We then create a function so that it can call itself and in it, we call getUsers. Now, if the operation succeeds, we will just call resolve with the value we received. The operation would function exactly like getUsers. However, when it fails, it checks the number of times it must retry and only fails (calling reject) when that number is zero. If it still has retries, it calls the f function we defined, with a timeout defined in the parameters. We finally call the f function just once.
Here is another example, something like the original get function, but that returns a Promise:
function get(url) { // Return a new promise. returnnew Promise(function(resolve, reject) { // Do the usual XHR stuff var req = new XMLHttpRequest(); req.open('GET', url);
req.onload = function() { // This is called even on 404 etc // so check the status if (req.status == 200) { // Resolve the promise with the response text resolve(req.response); } else { // Otherwise reject with the status text // which will hopefully be a meaningful error reject(Error(req.statusText)); } };
An interesting thing to remember is that the .then() method also returns a Promise, so one can do stuff like get('/users').then(JSON.parse).then(function(users) { ... }). If the function called by .then() is returning a Promise, then that is what .then() will return, allowing for stuff like someOperation().then(someOtherOperation).catch(errorForFirstOperation).then(handlerForSecondOperation). There is a lot more about promises in the Introduction in the link above and I won't copy/paste it here.
The nice thing about Promises is that they have been around in the Javascript world since forever in various libraries, but only recently as native Javascript objects. They have reached a maturity that was tested through the various implementations that led to the one accepted today by the major browsers.
Promises solve some of the problems in constructing a flow of asynchronous operations. They make the code cleaner and get rid of so many ugly extra callback parameters that many frameworks used us to. This flexibility is possible because in Javascript functions are first class members, meaning they can be passed around and manipulated just like any other parameter type.
The disadvantages are more subtle. Some parts of your code will be synchronous in nature. You will have stuff like a=sum(b,c); in functions that return values. Suddenly, functions don't return actual values, but promised values. The time they take to execute is also unclear. Everything is in flux.
Conclusion
I hope this has opened your eyes to the possibilities of writing your code in a way that is both more readable and easy to encapsulate. Promises are not limited to Javascript, many other languages have their own implementations. As I was saying in the intro, I feel like Promises are a simple subcase of Reactive Extensions streams in the sense that they act like data providers, but are limited to only one possible result. However, this simplicity may be more easy to implement and understand when this is the only scenario that needs to be handled.
 In Fevre Dream, George R. R. Martin writes about a fat bearded guy with a large appetite and a passion for food that loves to be a boat captain. Write what you know, they say. Anyways, this book about vampires in the bayou feels really dated. It has been described as "Bram Stoker meets Mark Twain", so you can imagine how much; written in 1982, it feels like written by a Lovecraft contemporary.
In Fevre Dream, George R. R. Martin writes about a fat bearded guy with a large appetite and a passion for food that loves to be a boat captain. Write what you know, they say. Anyways, this book about vampires in the bayou feels really dated. It has been described as "Bram Stoker meets Mark Twain", so you can imagine how much; written in 1982, it feels like written by a Lovecraft contemporary.


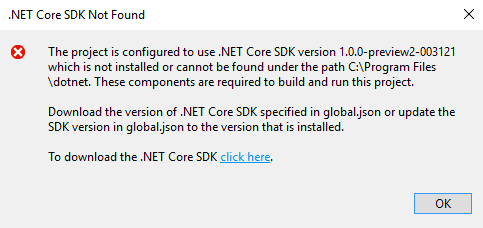



{kind=link}
{kind=link}
{kind=link}
{kind=link}