Using Kendo UI for jQuery MultiSelect with dynamic values
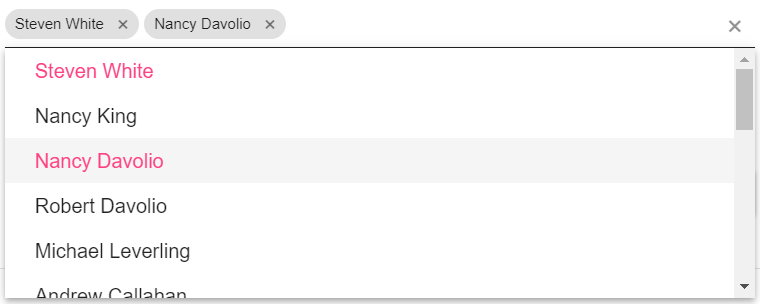
MultiSelect is a Kendo UI control that transforms a select element into a nice dropdown with text filtering which allows the selection of multiple items. This is how you use the same control to write values directly in the list, something akin to the Outlook address bar functionality.
Long story short: the control exposes some events like: 'filtering','open','close' and 'change'. In the filtering event, which is fired by someone writing or pasting text in order to filter the list of items, we dynamically create a list item that holds that value, so that the user can just press Enter and enter the value in the list. The code also allows for a custom transformation function, so for example someone could enter "1,2,3" and it would be translated into three values 1, 2 and 3 instead of an item with the value "1,2,3". On the close and change events we clear the items in the list that have not been selected. This means you cannot use this code as is to show an autocomplete list and also add dynamic values, but it is easy to tweak for that purpose.
In order to use it, instead of doing $(selector).kendoMultiSelect(options), just use $(selector).kendoDynamicMultiSelect(options). Here is the code:
$.fn.kendoDynamicMultiSelect = function (options) {
var multiSelect = $(this).kendoMultiSelect(options).getKendoMultiSelect();
multiSelect.bind('filtering', function (ev) {
var val = ev.filter && ev.filter.value;
if (!val) return;
var dataSource = ev.sender.dataSource;
var items = dataSource.data();
// if there is an existing item in the list, don't create a new one
var existingItem = items.filter(function (i) {
return i.value == val;
})[0];
if (existingItem) return;
// find or create the item that will hold the current filter value
var inputItem = items.filter(function (i) {
return i.isInput;
})[0];
if (!inputItem) {
inputItem = dataSource.insert(0, { isInput: true });
// when inserting a value the input gets cleared in some situations
// so set it back
ev.sender.input.val(ev.filter.value);
}
inputItem.value = val;
});
// cleans input items and also applies an optional value transformation function
var updateValues = function (ev) {
var values = ev.sender.value();
if (typeof options.valueTransformationFunction === 'function') {
// for example split comma separated values
values = options.valueTransformationFunction(values);
}
var dataSource = ev.sender.dataSource;
var items = dataSource.data();
for (var i = 0; i < items.length; i++) {
var item = items[i];
item.shouldBeKept = false;
}
// add items for existing values
for (var i = 0; i < values.length; i++) {
var value = values[i];
var item = items.filter(function (i) { return i.value == value; })[0];
if (!item) {
item = dataSource.add({ value: value });
}
item.isInput = false;
item.shouldBeKept = true;
}
ev.sender.value(values);
// delete all others
for (var i = 0; i < items.length; i++) {
var item = items[i];
if (!item.shouldBeKept) {
dataSource.remove(item);
}
}
};
multiSelect.bind('change', updateValues);
multiSelect.bind('close', updateValues);
};
I kind of copied this code by hand and tried it on another computer. If you find any bugs, let me know. Also, I know this is old time tech, but they use it in my company and I couldn't find this functionality by googling it, so here it is.
I hope it helps.


