
This is part of the .NET Core and VS Code series, which contains:
Since the release of .NET Core 1.1, a lot has changed, so I am trying to keep this up to date as much as possible, but there still might be some leftover obsolete info from earlier versions.
Continuing
the post about building a console application in .Net Core with the free Visual Studio Code tool on Windows, I will be looking at ASP.Net, also using Visual Studio Code. Some of the things required to understand this are in the previous post, so do read that one, at least for the part with installing Visual Studio Code and .NET Core.
Reading into it
Start with reading the
introduction to ASP.Net Core, take a look at the ASP.Net Core
Github repository and then continue with the information on the Microsoft sites, like the
Getting Started section. Much more effort went into the documentation for ASP.Net Core, which shows - to my chagrin - that the web is a primary focus for the .Net team, unlike the language itself, native console apps, WPF and so on. Or maybe they're just working on it.
Hello World - web style
Let's get right into it. Following the Getting Started section, I will display the steps required to create a working web Hello World application, then we continue with details of implementation for common scenarios. Surprisingly, creating a web app in .Net Core is very similar to doing a console app; in fact we could just continue with the console program we wrote in the first post and it would work just fine, even without a 'web' section in launch.json.
- Go to the Explorer icon and click on Open Folder (or File → Open Folder)
- Create a Code Hello World folder
- Right click under the folder in Explorer and choose Open in Command Prompt - if you have it. Some Windows versions removed this option from their context menu. If not, select Open in New Window, go to the File menu and select Open Command Prompt (as Administrator, if you can) from there
- Write 'dotnet new console' in the console window, then close the command prompt and the Windows Explorer window, if you needed it
- Select the newly created Code Hello World folder
- From the open folder, open Program.cs
- To the warning "Required assets to build and debug are missing from your project. Add them?" click Yes
- To the info "There are unresolved dependencies from '<your project>.csproj'. Please execute the restore command to continue." click Restore
- Click the Debug icon and press the green play arrow
Wait! Aren't these the steps for a console app? Yes they are. To turn this into a web application, we have to go through these few more steps:
Open project.json and add ,"Microsoft.AspNetCore.Server.Kestrel": "1.0.0"
to dependencies (right after Microsoft.NETCore.App)- Open the .csproj file and add
<ItemGroup>
<PackageReference Include="Microsoft.AspNetCore" Version="1.1.1" />
</ItemGroup>
- Open Program.cs and change it by adding
using Microsoft.AspNetCore.Hosting;
and replacing the Console.WriteLine thing with var host = new WebHostBuilder()
.UseKestrel()
.UseStartup<Startup>()
.Build();
host.Run();
- Create a new file called Startup.cs that looks like this:
using System;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.Http;
namespace <your namespace here>
{
public class Startup
{
public void Configure(IApplicationBuilder app)
{
app.Run(context =>
{
return context.Response.WriteAsync("Hello from ASP.NET Core!");
});
}
}
}
There are a lot of warnings and errors displayed, but the program compiles and when run it keeps running until stopped. To see the result open a browser window on
http://localhost:5000. Closing and reopening the folder will make the warnings go away.
#WhatHaveWeDone
So first we added Microsoft.AspNetCore.Server.Kestrel to the project. We added the Microsoft.AspNetCore namespace to the project. With this we have now access to the
Microsoft.AspNetCore.Hosting which allows us to use a fluent interface to build a web host. We UseKestrel (
Kestrel is based on libuv, which is a multi-platform support library with a focus on asynchronous I/O. It was primarily developed for use by Node.js, but it's also used by Luvit, Julia, pyuv, and others.) and we UseStartup with a class creatively named Startup. In that Startup class we receive an
IApplicationBuilder in the Configure method, to which we attach a simple handler on Run.
In order to understand the delegate sent to the application builder we need to go through the concept of
Middleware, which are components in a pipeline. In our case
Run was used, because as a convention Run is the last thing to be executed in the pipeline. We could have used just as well
Use without invoking the next component. Another option is to use
Map, which is also a convention exposed through an extension method like Run, and which is meant to branch the pipeline.
Anyway, all of this you can read in the documentation. A must read is the
Fundamentals section.
Various useful things
Let's ponder on what we would like in a real life web site. Obviously we need a web server that responds differently for different URLs, but we also need logging, security, static files. Boilerplate such as errors in the pages and not found pages need to be handled. So let's see how we can do this. Some tutorials are available on how to do that with Visual Studio, but in this post we will be doing this with Code! Instead of fully creating a web site, though, I will be adding to the basic Hello World above one or two features at a time, postponing building a fully functioning source for another blog post.
Logging
We will always need a way of knowing what our application is doing and for this we will implement a more complete Configure method in our Startup class. Instead of only accepting an IApplicationBuilder, we will also be asking for an
ILoggerFactory.
The main package needed for logging is "Microsoft.Extensions.Logging": "1.0.0"
, which needs to be added to dependencies in project.json. From .NET Core 1.1, Logging is included in the Microsoft.AspNetCore package.
Here is some code:
Startup.cs
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.Logging;
namespace ConsoleApplication
{
public class Startup
{
public void Configure(IApplicationBuilder app, ILoggerFactory loggerFactory)
{
var logger=loggerFactory.CreateLogger("Sample app logger");
logger.LogInformation("Starting app");
}
}
}
project.json {
"version": "1.0.0-*",
"buildOptions": {
"debugType": "portable",
"emitEntryPoint": true
},
"dependencies": {},
"frameworks": {
"netcoreapp1.0": {
"dependencies": {
"Microsoft.NETCore.App": {
"type": "platform",
"version": "1.0.0"
},
"Microsoft.AspNetCore.Server.Kestrel": "1.0.0",
"Microsoft.Extensions.Logging": "1.0.0"
},
"imports": "dnxcore50"
}
}
}
So far so good, but where does the logger log? For that matter, why do I need a logger factory, can't I just instantiate my own logger and use it? The logging mechanism intended by the developers is this: you get the logger factory, you add logger providers to it, which in turn instantiate logger instances. So when the logger factory creates a logger, it actually gives you a chain of different loggers, each with their own settings.
For example, in order to log to the console, you run
loggerFactory.AddConsole(); for which you need to add the package
"Microsoft.Extensions.Logging.Console": "1.0.0"
to project.json. What AddConsole does is actually
factory.AddProvider(new ConsoleLoggerProvider(...));. The provider will then instantiate a ConsoleLogger for the logger chain, which will write to the console.
Additional logging options come with the Debug or EventLog or EventSource packages as you can see at the
GitHub repository for Logging. Find a good tutorial on how to create your own Logger
here.
Static files
It wouldn't be much of a web server if it wouldn't serve static files. ASP.Net Core has two concepts for web site roots: Web root and Content root.
Web is for web-servable content files, while
Content is for application content files, like views and stuff. In order to serve these we use the
<PackageReference Include="Microsoft.AspNetCore.StaticFiles" Version="1.1.1" />
package, we instruct the WebHostBuilder what the web root is, then we tell the ApplicationBuilder to use static files. Like this:
project.json {
"version": "1.0.0-*",
"buildOptions": {
"debugType": "portable",
"emitEntryPoint": true
},
"dependencies": {},
"frameworks": {
"netcoreapp1.0": {
"dependencies": {
"Microsoft.NETCore.App": {
"type": "platform",
"version": "1.0.0"
},
"Microsoft.AspNetCore.Server.Kestrel": "1.0.0",
"Microsoft.AspNetCore.StaticFiles": "1.0.0"
},
"imports": "dnxcore50"
}
}
}.csproj file
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp1.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.AspNetCore" Version="1.1.1" />
<PackageReference Include="Microsoft.AspNetCore.StaticFiles" Version="1.1.1" />
</ItemGroup>
</Project>
Program.cs
using System.IO;
using Microsoft.AspNetCore.Hosting;
namespace ConsoleApplication
{
public class Program
{
public static void Main(string[] args)
{
var path=Path.Combine(Directory.GetCurrentDirectory(),"www");
var host = new WebHostBuilder()
.UseKestrel()
.UseWebRoot(path)
.UseStartup<Startup>()
.Build();
host.Run();
}
}
}
Startup.cs
using Microsoft.AspNetCore.Builder;
namespace ConsoleApplication
{
public class Startup
{
public void Configure(IApplicationBuilder app)
{
app.UseStaticFiles();
}
}
}
Now all we have to do is add a page and some files in the
www folder of our app and we have a web server. But what does
UseStaticFiles do? It runs
app.UseMiddleware(), which adds
StaticFilesMiddleware to the middleware chain which, after some validations and checks, runs
StaticFileContext.SendRangeAsync(). It is worth looking up the code of these files, since it both demystifies the magic of web servers and awes through simplicity.
Routing
Surely we need to serve static content, but what about dynamic content? Here is where routing comes into place.
First add package "Microsoft.AspNetCore.Routing": "1.0.0"
to project.json, then add some silly routing to Startup.cs:
project.json {
"version": "1.0.0-*",
"buildOptions": {
"debugType": "portable",
"emitEntryPoint": true
},
"dependencies": {},
"frameworks": {
"netcoreapp1.0": {
"dependencies": {
"Microsoft.NETCore.App": {
"type": "platform",
"version": "1.0.0"
},
"Microsoft.AspNetCore.Server.Kestrel": "1.0.0",
"Microsoft.AspNetCore.Routing": "1.0.0"
},
"imports": "dnxcore50"
}
}
}From .NET Core 1.1, Routing is found in the Microsoft.AspNetCore package.
Program.cs
using Microsoft.AspNetCore.Hosting;
namespace ConsoleApplication
{
public class Program
{
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseStartup<Startup>()
.Build();
host.Run();
}
}
}
Startup.cs
using System;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Routing;
using Microsoft.Extensions.DependencyInjection;
namespace ConsoleApplication
{
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddRouting();
}
public void Configure(IApplicationBuilder app)
{
app.UseRouter(new HelloRouter());
}
public class HelloRouter : IRouter
{
public VirtualPathData GetVirtualPath(VirtualPathContext context)
{
return null;
}
public Task RouteAsync(RouteContext context)
{
var requestPath = context.HttpContext.Request.Path;
if (requestPath.StartsWithSegments("/hello", StringComparison.OrdinalIgnoreCase))
{
context.Handler = async c =>
{
await c.Response.WriteAsync($"Hello world!");
};
}
return Task.FromResult(0);
}
}
}
}
Some interesting things added here. First of all, we added a new method to the Startup class, called ConfigureServices, which receives an IServicesCollection. To this, we
AddRouting, with a familiar by now extension method that shortcuts to adding a whole bunch of services to the collection: contraint resolvers, url encoders, route builders, routing marker services and so on. Then in Configure we UseRouter (shortcut for using a RouterMiddleware) with a custom built implementation of IRouter. What it does is look for a /hello URL request and returns the "Hello World!" string. Go on and test it by going to
http://localhost:5000/hello.
Take a look at the documentation for
routing for a proper example, specifically using a RouteBuilder to build an implementation of IRouter from a default handler and a list of mapped routes with their handlers and how to map routes, with parameters and constraints. Another post will handle a complete web site, but for now, let's just build a router with several routes, see how it goes:
Startup.cs
using System;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Routing;
using Microsoft.Extensions.DependencyInjection;
namespace ConsoleApplication
{
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddRouting();
}
public void Configure(IApplicationBuilder app)
{
var defaultHandler = new RouteHandler(
c => c.Response.WriteAsync($"Default handler! Route values: {string.Join(", ", c.GetRouteData().Values)}")
);
var routeBuilder = new RouteBuilder(app, defaultHandler);
routeBuilder.Routes.Add(new Route(new HelloRouter(), "hello/{name:alpha?}",
app.ApplicationServices.GetService<IInlineConstraintResolver>()));
routeBuilder.MapRoute("Track Package Route",
"package/{operation:regex(track|create|detonate)}/{id:int}");
var router = routeBuilder.Build();
app.UseRouter(router);
}
public class HelloRouter : IRouter
{
public VirtualPathData GetVirtualPath(VirtualPathContext context)
{
return null;
}
public Task RouteAsync(RouteContext context)
{
var name = context.RouteData.Values["name"] as string;
if (String.IsNullOrEmpty(name)) name="World";
var requestPath = context.HttpContext.Request.Path;
if (requestPath.StartsWithSegments("/hello", StringComparison.OrdinalIgnoreCase))
{
context.Handler = async c =>
{
await c.Response.WriteAsync($"Hi, {name}!");
};
}
return Task.FromResult(0);
}
}
}
}
Run it and test the following URLs:
http://localhost:5000/ - should return nothing but a 404 code (which you can check in the Network section of your browser's developer tools),
http://localhost:5000/hello - should display "Hi, World!",
http://localhost:5000/hello/Siderite - should display "Hi, Siderite!",
http://localhost:5000/package/track/12 - should display "Default handler! Route values: [operation, track], [id, 12]",
http://localhost:5000/track/abc - should again return a 404 code, since there is a constraint on id to be an integer.
How does that work? First of all we added a more complex HelloRouter implementation that handles a name. To the route builder we added a default handler that just displays the parameters receives, a Route instance that contains the URL template, the IRouter implementation and an inline constraint resolver for the parameter and finally we added just a mapped route that goes to the default router. That is why if no hello or package URL template are matched the site returns 404 and otherwise it chooses one handler or another and displays the result.
Error handling
Speaking of 404 code that can only be seen in the browser's developer tools, how do we display an error page? As usual, read
the documentation to understand things fully, but for now we will be playing around with the routing example above and adding error handling to it.
The short answer is add some middleware to the mix. Extensions methods
in "Microsoft.AspNetCore.Diagnostics": "1.0.0"
like
UseStatusCodePages, UseStatusCodePagesWithRedirects, UseStatusCodePagesWithReExecute,
UseDeveloperExceptionPage,
UseExceptionHandler.
Here is an example of the Startup class:
using System;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Routing;
using Microsoft.Extensions.DependencyInjection;
namespace ConsoleApplication
{
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddRouting();
}
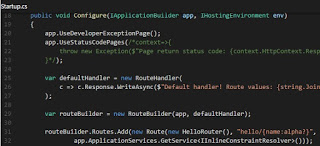
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
app.UseDeveloperExceptionPage();
app.UseStatusCodePages(/*context=>{
throw new Exception($"Page return status code: {context.HttpContext.Response.StatusCode}");
}*/);
var defaultHandler = new RouteHandler(
c => c.Response.WriteAsync($"Default handler! Route values: {string.Join(", ", c.GetRouteData().Values)}")
);
var routeBuilder = new RouteBuilder(app, defaultHandler);
routeBuilder.Routes.Add(new Route(new HelloRouter(), "hello/{name:alpha?}",
app.ApplicationServices.GetService<IInlineConstraintResolver>()));
routeBuilder.MapRoute("Track Package Route",
"package/{operation:regex(track|create|detonate)}/{id:int}");
var router = routeBuilder.Build();
app.UseRouter(router);
}
public class HelloRouter : IRouter
{
public VirtualPathData GetVirtualPath(VirtualPathContext context)
{
return null;
}
public Task RouteAsync(RouteContext context)
{
var name = context.RouteData.Values["name"] as string;
if (String.IsNullOrEmpty(name)) name = "World";
if (String.Equals(name, "error", StringComparison.OrdinalIgnoreCase))
{
throw new ArgumentException("Hate errors! Won't say Hi!");
}
var requestPath = context.HttpContext.Request.Path;
if (requestPath.StartsWithSegments("/hello", StringComparison.OrdinalIgnoreCase))
{
context.Handler = async c =>
{
await c.Response.WriteAsync($"Hi, {name}!");
};
}
return Task.FromResult(0);
}
}
}
}
All you have to do now is try some non existent route like
http://localhost:5000/help or cause an error with
http://localhost:5000/hello/errorFinal thoughts
The post is already too long so I won't be covering here a lot of what is needed such as security or setting the environment name so one can, for example, only show the development error page for the development environment. The VS Code ecosystem is at its beginning and work is being done to improve it as we speak. The basic concept of middleware allows us to build whatever we want, starting from scratch. In a future post I will discuss MVC and Web API and the more advanced concepts related to the web. Perhaps it will be done in VS Code as well, perhaps not, but my point is that with the knowledge so far one can control all of these things by knowing how to handle a few classes in a list of middleware. You might not need an off the shelf framework, you may write your own.
Find a melange of the code above in this
GitHub repository.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}