 Update 29 August 2017 - Version 3.0.4:
Update 29 August 2017 - Version 3.0.4: The extension has been rewritten in EcmaScript6 and tested on
Chrome,
Firefox and
Opera.
Update 03 March 2017 - Version 2.9.3: added a function to remove marketing URLs from all created bookmarks. Enable it in the Advanced settings section. Please let me know of any particular parameters you need purged. So far it removes utm_*, wkey, wemail, _hsenc, _hsmi and hsCtaTracking.
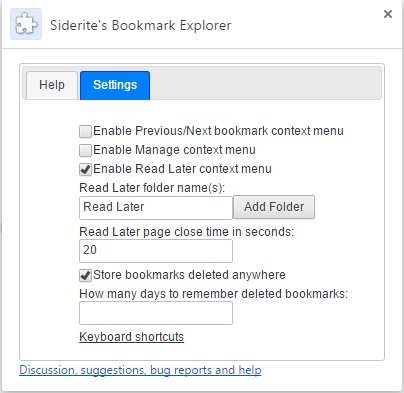
Update 26 February 2017: Version (2.9.1): added customizing the URL comparison function. People can choose what makes pages different in general or for specific URL patternsUpdate 13 June 2016: Stable version (2.5.0): added Settings page, Read Later functionality, undelete bookmarks page and much more.Update 8 May 2016: Rewritten the extension from scratch, with unit testing.Update 28 March 2016: The entire source code of the extension is now open sourced at GitHub. Whenever I read my news, I open a bookmark folder containing my favorite news sites, Twitter, Facebook, etc. I then proceed to open new tabs for each link I find interesting, closing the originating links when I am done. Usually I get a number of 30-60 open tabs. This wreaks havoc on my memory and computer responsiveness. And it's really stupid, because I only need to read them one by one. In the end I've decided to fight my laziness and create my first browser extension to help me out.
The extension is published here:
Siderite's Bookmark Explorer and what it does is check if the current page is found in any bookmark folder, then allow you to go forward or backwards inside that folder.
So this is my scenario on using it:
- Open the sites that you want to get the links from.
- Open new tabs for the articles you want to read or YouTube videos you want to watch,etc.
- Bookmark all tabs into a folder.
- Close all the tabs.
- Navigate to the bookmark folder and open the first link.
- Read the link, then press the Bookmark Navigator button and then the right arrow. (now added support for context menu and keyboard shortcuts)
- If you went too far by mistake, press the left arrow to go back.
OK, let's talk about how I did it. In order to create your own Chrome browser extension you need to follow these steps:
1. Create the folder
Create a folder and put inside a file called
manifest.json. It's
possible structure is pretty complex, but let's start with what I used:
{
"manifest_version" : 2,
"name" : "Siderite's Bookmark Explorer",
"description" : "Gives you a nice Next button to go to the next bookmark in the folder",
"version" : "1.0.2",
"permissions" : [
"tabs",
"activeTab",
"bookmarks",
"contextMenus"
],
"browser_action" : {
"default_icon" : "icon.png",
"default_popup" : "popup.html"
},
"background" : {
"scripts" : ["background.js"],
"persistent" : false
},
"commands" : {
"prevBookmark" : {
"suggested_key" : {
"default" : "Ctrl+Shift+K"
},
"description" : "Navigate to previous bookmark in the folder"
},
"nextBookmark" : {
"suggested_key" : {
"default" : "Ctrl+Shift+L"
},
"description" : "Navigate to next bookmark in the folder"
}
}
}
The manifest version must be 2. You need a name, a description and a version number. Start with something small, like 0.0.1, as you will want to increase the value as you make changes. The other thing is that mandatory is the
permissions object, which tells the browser what Chrome APIs you intend to use. I've set there
activeTab, because I want to know what the active tab is and what is its URL,
tabs, because I might want to get the tab by id and then I don't get info like URL if I didn't specify this permission,
bookmarks, because I want to access the bookmarks, and
contextMenus, because I want to add items in the page context menu. More on permissions
here.
Now, we need to know what the extension should behave like.
If you want to
click on it and get a popup that does stuff, you need to specify the
browser_action object, where you specify the icon that you want to have in the Chrome extensions bar and/or the popup page that you want to open. If you don't specify this, you get a default button that does nothing on click and presents the standard context menu on right click. You may only specify the icon, though. More on browserAction
here.
If you want to have an extension that
reacts to background events, monitors URL changes on the current page, responds to commands, then you need a
background page. Here I specify that the page is a javascript, but you can add HTML and CSS and other stuff as well. More on background
here.
Obviously, the files mentioned in the manifest must be created in the same folder.
The last item in the manifest is the
commands object. For each command you need to define the id, the keyboard shortcut (only the 0..9 and A..Z are usable unfortunately) and a description. In order to respond to commands you need a background page as shown above.
2. Test the extension
Next you open a Chrome tab and go to
chrome://extensions, click on the 'Developer mode' checkbox if it is not checked already and you get a Load unpacked extension button. Click it and point the following dialog to your folder and test that everything works OK.
3. Publish your extension
In order to publish your extension you need to have a Chrome Web Store account. Go to
Chrome Web Store Developer Dashboard and create one. You will need to pay a one time 5$ fee to open it. I know, it kind of sucks, but I paid it and was done with it.
Next, you need to Add New Item, where you will be asked for a packed extension, which is nothing but the ZIP archive of all the files in your folder.
That's it.
Let's now discuss actual implementation details.
Adding functionality to popup elements
Getting the popup page elements is easy with vanilla Javascript, because we know we are building for only one browser: Chrome! So getting elements is done via document.getElementById(id), for example, and adding functionality is done via elem.addEventListener(event,handler,false);
One can use the elements as objects directly to set values that are related to those elements. For example my prev/next button functionality takes the URL from the button itself and changes the location of the current tab to that value. Code executed when the popup opens sets the 'url' property on the button object.
Just remember to do it when the popup has finished loading (with document.addEventListener('DOMContentLoaded', function () { /*here*/ }); )
Getting the currently active tab
All the Chrome APIs are asynchronous, so the code is:
chrome.tabs.query({
'active' : true,
'lastFocusedWindow' : true
}, function (tabs) {
var tab = tabs[0];
if (!tab) return;
// do something with tab
});More on chrome.tabs
here.
Changing the URL of a tab
chrome.tabs.update(tab.id, {
url : url
});
Changing the icon in the Chrome extensions bar
if (chrome.browserAction) chrome.browserAction.setIcon({
path : {
'19' : 'anotherIcon.png'
},
tabId : tab.id
});
The icons are 19x19 PNG files.
browserAction may not be available, if not declared in the manifest.
Get bookmarks
Remember you need the
bookmarks permission in order for this to work.
chrome.bookmarks.getTree(function (tree) {
//do something with bookmarks
});
The tree is an array of items that have title and url or children. The first tree array item is the Bookmarks Bar, for example. More about bookmarks
here.
Hooking to Chrome events
chrome.tabs.onUpdated.addListener(refresh);
chrome.tabs.onCreated.addListener(refresh);
chrome.tabs.onActivated.addListener(refresh);
chrome.tabs.onActiveChanged.addListener(refresh);
chrome.contextMenus.onClicked.addListener(function (info, tab) {
navigate(info.menuItemId, tab);
});
chrome.commands.onCommand.addListener(function (command) {
navigate(command, null);
});
In order to get extended info on the tab object received by tabs events, you need the
tabs permission. For access to the contextMenus object you need the
contextMenus permission.
Warning: if you install your extension from the store and you disable it so you can test your unpacked extension, you will notice that keyboard commands do not work. Seems to be a bug in Chrome. The solution is to remove your extension completely so that the other version can hook into the keyboard shortcuts.
Creating, detecting and removing menu items
To create a menu item is very simple:
chrome.contextMenus.create({
"id" : "menuItemId",
"title" : "Menu item description",
"contexts" : ["page"] //where the menuItem will be available
});However, there is no way to 'get' a menu item and if you try to blindly remove a menu item with .remove(id) it will throw an exception. My solution was to use an object to store when I created and when I destroyed the menu items so I can safely call .remove().
To hook to the context menu events, use chrome.contextMenus.onClicked.addListener(function (info, tab) { }); where info contains the menuItemId property that is the same as the id used when creating the item.
Again, to access the context menu API, you need the
contextMenus permission. More about context menus
here.
Commands
You use commands basically to define keyboard shortcuts. You define them in your manifest and then you hook to the event with chrome.commands.onCommand.addListener(function (command) { });, where command is a string containing the key of the command.
Only modifiers, letters and digits can be used. Amazingly, you don't need permissions for using this API, but since commands are defined in the manifest, it would be superfluous, I guess.
That's it for what I wanted to discuss here. Any questions, bug reports, feature requests... use the comments in the post.
 I've decided the functionality of the Bookmark Explorer extension was pretty close to final and, before I refactor it to a new form, I wanted to make sure it works for all the browsers that support the WebExtensions mechanism, mainly Chrome, Firefox and Opera. Frankly, I have no idea why anyone would use Firefox or Opera, but if you do, I've got great news for you: I have published the extension for all of them:
I've decided the functionality of the Bookmark Explorer extension was pretty close to final and, before I refactor it to a new form, I wanted to make sure it works for all the browsers that support the WebExtensions mechanism, mainly Chrome, Firefox and Opera. Frankly, I have no idea why anyone would use Firefox or Opera, but if you do, I've got great news for you: I have published the extension for all of them:




{kind=link}