A friend of mine has been employed to write code in the new Microsoft cross-platform ASP.Net Mvc Core and one day he asked be about the difference between the [Required] and the [BindRequired] attributes. Not being an expert in ASP.Net MVC and even less in the Core version, I had no idea so I went exploring.
Fast and dirty
I created a small project and ran it several times to see what the attributes were doing. RequiredAttribute seemed to work quite straightforward: decorate a property of an object with it and, when used as a parameter in an MVC API controller method, that property needs to be set. If it is not, the Controller ModelState.IsValid value will be set to false. Something like this:
public IActionResult Test([FromBody]TestModel model)
TestModel is a simple POCO with Required and BindRequired attributes set on its properties:
publicclass TestModel { [Required] publicstring A { get; set; } [BindRequired] publicstring B { get; set; } }
Now, if I send an object like this
{ A:'Something',B:'Something else' }
I get a true ModelState.IsValid value. If I send only property A, I also get a valid model. If I send only B or an empty object, IsValid will be false. So [Required] works as expected, [BindRequired] doesn't seem to do anything.
Searching through the methods of the controller I noticed one in particular called TryUpdateModelAsync. It tries to populate a model, given as a parameter, with values from the URL or form parameters for the action method. That means if you call the API with something like /api/test/test&A=Something&B=SomethingElse then run
var valid = TryUpdateModelAsync(model).Result;
, valid will be true. However, if you fail to specify a B parameter, valid will be false. Note that the properties of the model change either way. Property A will be filled with whatever you send it, only the result of the attempt will be false.
My friend was not completely satisfied with what I discovered, but it was what I could do in a few minutes of work.
More work
Frankly, I wasn't satisfied either. The only mention I could find of this BindRequired attribute was in the ASP.Net Core documentation, thrown in a list together with [FromBody], which applied to parameters, not object properties, and in unit tests code. So I started digging.
I went to the GitHub repository for aspnet/Mvc and downloaded the source. I then looked for a class named BindRequiredAttribute. It is a very simple class that inherits from BindingBehaviorAttribute and sends BindingBehavior.Required as the base constructor parameter. Its description is "Indicates that a property is required for model binding. When applied to a property, the model binding system requires a value for that property. When applied to a type, the model binding system requires values for all properties of that type." This doesn't say much. So I started to go through the chain of extension methods, interfaces, dependency injection. It wasn't pretty. Let's just say that after a few pages of blog post where I described wandering through classes and properties and trying everything - you wouldn't have understood anything because I didn't - I've decided to delete everything and search the web for more information.
In the end, experimenting with the project is what made it clear(er) for me. In the example I created, the Test method received an object [FromBody], but if I removed that attribute, the content of the call to the API was ignored. Instead, the values from the URL or form POST would be used to fill the object - this explains why FromBody and BindRequired were grouped in the same list. So for the same code without [FromBody]:
public IActionResult Test(TestModel model)
and now the request /api/test/test&A=Something&B=SomethingElse fills the object without the need for content (and ignoring it if it exists). If I remove either A or B, ModelState.IsValid becomes false.
What does it mean?
To me it feels as the [Required] attribute is all that I need since it works in both cases: form values and content, however besides [BindRequired], there is also [BindNever], which removes that property from binding. Imagine you would have a property like "IsAdmin" and you would set it to true programatically - you don't want it to be bound from the URL of the call. I was expecting that attempting to set a property decorated with BindNever would invalidate the model state, but it doesn't work like that, it just ignores the parameter. The System.ComponentModel.DataAnnotations namespace doesn't have an equivalent to BindNeverAttribute.
There is also the issue of the many many many points where the behavior of MVC can be changed and customized. There are a lot of out of the box classes that come with ASP.Net MVC; it only makes sense to use Attribute classes from the same package.
What about the inconsistency? Why does a [BindRequired] attribute not matter when populating a model from the body of the request? Frankly, I don't know. I believe it is because in that case the entire model class has been "bound", its individual properties being "populated" instead.
Another entry from my ".NET with Visual Studio Code" series, this will discuss the default web site generated by the 'dotnet new' command. I recommend reading the previous articles:
Update 31 Mar 2017: This entire article is obsolete. Since the release of .NET Core 1.1 the dotnet command now has a different syntax: dotnet new <template> where it needs a template specified, doesn't default to console anymore. Also, the web template is really stripped down to only what one needs, similar to my changes to the console project to make it web. The project.json format has become deprecated and now .csproj files are being used. Yet I worked a lot on the post and it might show you how .NET Core came to be and how it changed in time.
The analysis that follows is now more appropriate for the dotnet new mvc template in .NET Core 1.1, although they removed the database access and other things like registration from it.
Setup
Creating the ASP.Net project
Until now we've used the simple 'dotnet new' command which defaults to the Console application project type. However, there are four available types that can be specified with the -t flag: Console,Web,Lib and xunittest. I want to use Visual Studio Code to explore the default web project generated by the command. So let's follow some basic steps:
Create a new folder
Open a command prompt in it (Update: Core has a Terminal window in it now, which one can use)
Type dotnet new -t Web
Open Visual Studio Code and select the newly created folder
To the prompt "Required assets to build and debug are missing from your project. Add them?" choose Yes
First of all there is a nice README.MD file that announces this is a big update of the .NET Core release and it's a good idea to read the documentation. It says that the application in the project consists of:
Sample pages using ASP.NET Core MVC
Gulp and Bower for managing client-side libraries
Theming using Bootstrap
and follows with a lot of how-to URLs that are mainly from the documentation pages for MVC and the MVC tutorial that uses Visual Studio proper. While we will certainly read all of that eventually, this series is more about exploring stuff rather than learning it from a tutorial.
If we go to the Debug section of Code and run the web site, two interesting things happen. One is that the project compiles! Yay! The other is that the web site at localhost:5000 is automatically opened. This happens because of the launchBrowser property in build.json's configuration:
The web site itself looks like crap, because there are some console errors of missing files like /lib/bootstrap/dist/css/bootstrap.css, /lib/bootstrap/dist/js/bootstrap.js, /lib/jquery/dist/jquery.js and /lib/bootstrap/dist/js/bootstrap.js. All of these files are Javascript and CSS files from frameworks defined in bower.json:
and there is also a .bowerrc file indicating the destination folder:
{ "directory": "wwwroot/lib" }
. This probably has to do with that Gulp and Bower line in the Readme file.
What is Bower? Apparently, it's a package manager that depends on node, npm and git. Could it be that I need to install Node.js just so that I can compile my C# ASP.Net project? Yes it could. That's pretty shitty if you ask me, but I may be a purist at heart and completely wrong.
Installing tools for client side package management
While ASP.Net Core's documentation about Client-Side Development explains some stuff about these tools, I found that Rule-of-Tech's tutorial from a year and a half ago explains better how to install and use them on Windows. For the purposes of this post I will not create my own .NET bower and gulp emulators and install the tools as instructed... and under duress. You're welcome, Internet!
Go to the Node.js site and install it. Certainly a pattern seems to emerge here. On their page they seem to offer two wildly different versions: one that is called LTS and has version v4.4.7, another that is called Current at version v6.3.0. A quick google later I know that LTS comes from 'Long Term Support' and is meant for corporate environments where change is rare and the need for specific version support much larger. I will install the Current version for myself.
Bower
The Bower web site indicates how to install it via the Node.js npm:
npm install -g bower
. Oh, you gotta love the ASCII colors and the loader! Soooo cuuuute!
Gulp
Install Gulp with npm as well:
npm install --global gulp
Here tutorials say to install it in your project's folder again:
npm install --save-dev gulp
Why do we need to install gulp twice, once globally and once locally? Because reasons. However, I noticed that in the project there is already a package.json containing what I need for the project:
without specifying a package and it installs what I need. The install immediately gave me some concerning warnings like "graceful-fs v3.0.0 will fail on node releases >=7.0. Please update to graceful-fs 4.0.0" and "please update to minimatch 3.0.2 or higher to avoid a RegExp DoS issue" and "lodash v3.0.0 is no longer maintained. Upgrade to lodash v4.0.0". Luckily, the error messages are soon replaced by a random ASCII tree and if you can't scroll up you're screwed :) One solution is to pipe the output to a file or to NUL so that the ASCII tree of the packages doesn't scroll the warnings up
npm install --save-dev >nul
Before I go into weird Linux reminiscent console warnings and fixes, let's see if we can now fix our web site, so I run "gulp" and I get the error "Task 'default' is not in your gulpfile. Please check the documentation for proper gulpfile formatting". Going back to the documentation I understand why: it's because there is no default task in the gulpfile! Well, it sounded more exciting in my head.
Long story short, the commands to be executed are in project.json, in the scripts section:
There is npm install, there is bower install and the two tasks for gulp: clean and min.
It was the bower command that we actually needed to make the web site load the frameworks needed. Phew!
Let's start the web site again, from Code, by going to Debug and clicking Run. (By now it should be working with F5, I guess) Victory! The web site looks grand. It works!
Remember that .NET Core is still version 1. As Microsoft has accustomed us for decades, you never use version 1 of any of their products. If you are in a hurry, you wait until version 2. If you care about your time, you wait for the second service pack of version 2. OK, a cheap shot, but how is it not frustrating to invest in something and then see it "phased out". Didn't they think things through?
Anyway, since the web site is working, I will postpone a rant about corporate vision and instead continue with the analysis of the project.
node_modules
Not only did I install Node and Bower and Gulp, but a lot of dependencies. The local installation folder for Node.js packages called node_modules is now 6MB of files that are mostly comments and boilerplate. It must be the (in)famous by now NPM ecosystem, where every little piece of functionality is a different project. At least nothing else seems to be polluted by it, so we will ignore it as a necessary evil.
Program and Startup
Following the pattern discussed in previous posts, the Program class is building the web host and then passing responsibility for configuration and management to the Startup class. The most obvious new thing in the class is the IConfigurationRoot instance that is built in the class' constructor.
public IConfigurationRoot Configuration { get; }
var builder = new ConfigurationBuilder() .SetBasePath(env.ContentRootPath) .AddJsonFile("appsettings.json", optional: true, reloadOnChange: true) .AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional: true);
Configuration = builder.Build();
Here is the appsettings.json file that is being loaded there:
I've tried to use the most relevant links up there, but you will note that some of them are from spring 2015. There is still much to be written about Core, so look it up yourselves.
Database
As you know, almost any application worth mentioning uses some sort of database. ASP.Net MVC uses an abstraction for that called ApplicationDbContext, which the Microsoft team wants us to use with Entity Framework. ApplicationDbContext just inherits from DbContext and links it to Identity via an ApplicationUser. If you unfamiliar on how to work with EF DbContexts, check out this link. In the default project the database work is instantiated with
AddDbContext is a way of injecting the DbContext without specifying an implementation. UseSqlite is an extension method that gets that implementation for you.
Let us test the functionality of the site so that I can get to an interesting EntityFramework concept called Migrations.
So, going to the now familiar localhost:5000 I notice a login/register link combo. I go to register, I enter a ridiculously convoluted password pattern and I get... an error:
A database operation failed while processing the request.
SqliteException: SQLite Error 1: 'no such table: AspNetUsers'.
Applying existing migrations for ApplicationDbContext may resolve this issue
There are migrations for ApplicationDbContext that have not been applied to the database
00000000000000_CreateIdentitySchema
In Visual Studio, you can use the Package Manager Console to apply pending migrations to the database:
PM> Update-Database
Alternatively, you can apply pending migrations from a command prompt at your project directory:
> dotnet ef database update
What is all that about? Well, in a folder called Data in our project there is a Migrations folder containing files 00000000000000_CreateIdentitySchema.cs, 00000000000000_CreateIdentitySchema.Designer.cs and ApplicationDbContextModelSnapshot.cs. They inherit from Migration and ModelSnapshot respectively and seem to describe in coade database structure and entities. Can it be as simple as running:
dotnet ef database update
(make sure you stop the running web server before you run the command)? It compiles the project and it completes in a few seconds. Let's run the app again and attempt to register. It works!
What happened? In the /bin directory of our project there is now a WebApplication.db file which, when opened, reveals it's an SQLite database.
But what about the mysterious button "Apply Migrations"? It generates an Ajax POST call to /ApplyDatabaseMigrations. Clicking it also fixes everything. How does that work? I mean, there is no controller for an ApplyDatabaseMigrations call. It all comes from the line
if (env.IsDevelopment()) { ... app.UseDatabaseErrorPage(); ... }
It is a good idea to install SQLite as a standalone application. Make sure you install both binaries for the library as well as the client (the library might be x64 and the client x86). The installation is brutally manual. You need to copy both library and client files in a folder, let's say C:\Program Files\SQLite and then add the folder in the PATH environment variable. An alternative is using the free SQLiteBrowser app.
Opening the database with SQLiteBrowser we find tables for Users, Roles, Claims and Tokens, what we would expect from a user identity management system. However, only the Users table was used when creating a new user.
Controllers
The controllers of the application contain the last ASP.Net related functionality of the project, anything else is business logic. The controllers themselves, though, are nothing special in terms of Core. The same class names, the same attributes, the same functionality as any regular MVC. I am not a specialist in that and I believe it to be outside the scope of the current blog post. However it is important to look inside these classes and the ones that are used by them so that we understand at least the basic concepts the creators of the project wanted to teach us. So I will quickly go through them, no code, just conceptual ideas:
HomeController - the simplest possible controller, it displays the home view
AccountController and ManageController - responsible for account management, they have a lot of functionality including antiforgery token, forgot the password, external login providers, two factor authentication, email and SMS sending, reset password, change email, etc. Of course, register, login and logoff.
IEmailSender, ISMSSender and MessageServices - if we waited until this moment for me to reveal the simple and free email/SMS provider architecture in the project, you will be disappointed. MessageServices implements both IEmailSender and ISMSSender with empty methods where you should plus useful code.
Views - all views are interesting to explore. They show basic and sometimes not so basics concepts of Razor Model/View/Controller interaction like: imports, declaring the controller and action names in the form element instead of a string URL, declaring the @model type for a view, validation summaries, inline code, partial views, model to view synchronization, variable view content depending on environment (production, staging), fallback source and automated testing that the script loaded, bootstrap theming, etc.
Models - model classes are simple POCOs, but they do provide their occasional instruction, like using annotations for data structure, validation and display purposes alike
Running the website
So far I've described running the web site through the Debug sidebar, but how do I run the website from the command line? Simply by running
dotnet run
in your project folder. You can just as well use
dotnet compiled.dll
, but you need to also run it from the project root. In the former case, dotnet will also compile the project for you, in the latter it will just run whatever is already compiled.
In order to change the default IP and port binding, refer to this answer on Stack Overflow. Long story short, you need to use a configuration file from your WebHostBuilder setup.
However there is a lot of talk about dnx. What is this? In short, it's 'dotnet'. Before version 1 there was an entire list of commands like dnvm, dnu, dnx, etc. You may still install them if you want, but I wouldn't recommend it. As detailed in this document, the transition from the dn* tools to the dotnet command is already in progress.
Conclusions
A large number of concepts have been bundled together in the default "web" project type, allowing for someone to immediately create and run a web site, theme it and change it to their own purposes. While creating such a project from Visual Studio is a breeze compared to what I've described, it is still a big step towards enabling people to just quickly install some stuff and immediately start coding. I approve! :) good job, Microsoft!
Since the release of .NET Core 1.1, a lot has changed, so I am trying to keep this up to date as much as possible, but there still might be some leftover obsolete info from earlier versions.
I am continuing my series about .NET Core, using Visual Studio Code only, on Windows, with as little command line work as possible. Read about writing a console application and then a very simple web application before you read this part.
Setup
In this post I will attempt to write a very simple Web API using .NET Core. I intend to have some sort of authentication and then be able to read and write stuff using REST API calls. As with the projects before, I will use Visual Studio Code to create a folder, open it, then do stuff in it after running the command 'dotnet new' and preferably changing the namespace so that it is not always ConsoleApplication. This time the steps will be a little bit different, more inline with what you would do in real life:
Create a folder for our project called WebCore
In it create an API folder
Open a command prompt in the API folder and type 'dotnet new web' (in .NET Core 1.0 you could omit the template, but from 1.1 you need to use it explicitly)
Open Visual Studio Code by typing 'code' or by any other means
Close the command prompt window
In Code select the API folder and open Program.cs
To the warning "Required assets to build and debug are missing from your project. Add them?" click Yes
To the info "There are unresolved dependencies from '<your project>.csproj'. Please execute the restore command to continue." click Restore
Change the namespace to WebCore.API
Press Ctrl-Shift-B to build the project.
Right now you should have a web project that compiles. In order to turn this into an API project, we need to understand a few things. So go down to the tutorial for ASP.Net Core API that uses Visual Studio to read about what Microsoft suggests, download the zip file of all the docs and tutorials and look in /Docs-master/aspnet/tutorials/first-web-api/sample/src/TodoApi to see what they did in code (or just browse them on GitHub). You also need to understand that while in normal .NET (how do we call it now?) MVC and Web API are two branches that often have similar functionality in similarly named classes, in .NET Core the API is just part of MVC. So no WebApi namespaces, just MVC.
That is why, to turn our app into an API project we need to add to the dependencies of project.json the MVC packages:
to ItemGroup in API.csproj and tell the project to use MVC in code. This is done by adding services.AddMvc(); in ConfigureServices and replacing the app.Run line in Configure with app.UseMvcWithDefaultRoute(); in Program.cs.
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Threading.Tasks; using Microsoft.AspNetCore.Hosting;
namespace WebCore.API { publicclass Program { publicstaticvoid Main(string[] args) { var host = new WebHostBuilder() .UseKestrel() .UseContentRoot(Directory.GetCurrentDirectory()) .UseIISIntegration() .UseStartup<Startup>() .Build();
host.Run(); } } }
Startup.cs
using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using Microsoft.AspNetCore.Builder; using Microsoft.AspNetCore.Hosting; using Microsoft.AspNetCore.Http; using Microsoft.Extensions.DependencyInjection; using Microsoft.Extensions.Logging;
namespace WebCore.API { publicclass Startup { // This method gets called by the runtime. Use this method to add services to the container. // For more information on how to configure your application, visit https://go.microsoft.com/fwlink/?LinkID=398940 publicvoid ConfigureServices(IServiceCollection services) { services.AddMvc(); }
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline. publicvoid Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory) { loggerFactory.AddConsole();
if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); }
Let's add functionality to our API. Create a folder called Controllers and in it add a NoteController.cs file. Just copy paste the code for now, we will understand it later.
using System.Collections.Generic; using Microsoft.AspNetCore.Mvc;
In this new class we have a lot of interesting things to behold. First of all there is the Route attribute that uses a [controller] token (well explained here). Then there are the Http attributes: HttpGet, HttpPost, HttpPut, HttpDelete which as their name implies define methods on the API controller that are accessed via the respective HTTP methods so beloved by the REST crowd.
An important thing to grasp from this is what happens with the HttpGet attribute (note it has a Name defined) and the later used CreatedAtRoute, which are actually Web API v2 concepts. In our case, whenever we create a new item we return the item as a result, but also set the Location header to the route that would "get" it, so that the client knows how to get to it.
Testing the result
Let's test what we did. While the GET methods are easy to test from the browser (http://localhost:5000/api/note should show an empty array result []), the POST and DELETE are trickier. The Microsoft documentation recommends using Fiddler, but I would go with the easy to install as a Chrome application Postman.
In Postman, don't forget to set the Content-Type header to application/json:
What happened there exactly? We just added a class and it magically worked. How did .Net Core to do that? Core comes with Dependency Injection and Inversion of Control by default. In our case, just because we have a Controller class with a Route attribute made the difference. The line
app.UseMvcWithDefaultRoute();
is the code that enables that behavior. Let me demonstrate more of this "magic". In our example so far I've hardcoded the Note class inside the Controller class, but usually the class would be part of the functionality of the API and there would be a repository handling saving stuff in the database.
To avoid polluting the post with a lot of code, here is the improved source code of the API. Note is now a more complex object, the controller is initialized with a INoteRepository instance which is bound to a NoteRepository implementation. The API works just as before, only now Note has Key, Subject and Body properties instead of Id and Content.
The thing to learn from this version is how in the Startup class, in ConfigureServices the line
services.AddSingleton();
we tell Core that for a request of the implementation for INoteRepository, return the singleton instance of NoteRepository. From this line alone Core knows to initialize the NoteController constructor with the correct repository instance.
Security
Now, we don't want any peasant to come and mess with our important notes. We require some way of authenticating our operations. There is a very detailed section about Security in the Core documentation, but I only wanted a simple example. I worked on it for hours just to notice that line instructing the application builder to use authentication was after the one telling it to use MVC. Also some naming bugs that made me waste a lot of time.
Bottom line: here is the sample code with authentication. You cannot use any API calls unless you are a User. You login as a user calling /api/note/login/12345. The Create/Delete APIs are also unavailable to the Users, you need to be an Admin. There is a commented line in the code that also adds the Claim to the Admin role when logging in. I also added logging, so you can see what goes wrong in the Debug Console.
Update: some of the complaints underneath are not correct anymore, but I am keeping my original reaction unchanged, since it reflects my feelings at the time.
The more complex the project becomes, the less Visual Studio Code can handle it. Intellisense is bloody awful, the exceptions can sometimes be caught only by adding logging to the console, the basic editing features are lacking - like a serious Undo queue or auto formatting when typing or closing brackets or even syntax highlighting at times and there are some features that plainly don't work, for example when you are writing a new class and an option for "Generate Type" appears, but it does nothing. Same for "Generate Variable". While I plan to test VS Code with a large project created in Visual Studio proper, I don't have high hopes. Remember when Microsoft created Silverlight with Javascript and it sucked and they immediately switched to WPF based Silverlight? It feels like that. However, for nostalgic reasons mostly, I also enjoy working in this spartan environment, especially when working with recently released features. It reminds me of the days when I was trying to connect various Linux software with basically duct tape and paper clips.
Since the release of .NET Core 1.1, a lot has changed, so I am trying to keep this up to date as much as possible, but there still might be some leftover obsolete info from earlier versions.
Continuing the post about building a console application in .Net Core with the free Visual Studio Code tool on Windows, I will be looking at ASP.Net, also using Visual Studio Code. Some of the things required to understand this are in the previous post, so do read that one, at least for the part with installing Visual Studio Code and .NET Core.
Reading into it
Start with reading the introduction to ASP.Net Core, take a look at the ASP.Net Core Github repository and then continue with the information on the Microsoft sites, like the Getting Started section. Much more effort went into the documentation for ASP.Net Core, which shows - to my chagrin - that the web is a primary focus for the .Net team, unlike the language itself, native console apps, WPF and so on. Or maybe they're just working on it.
Hello World - web style
Let's get right into it. Following the Getting Started section, I will display the steps required to create a working web Hello World application, then we continue with details of implementation for common scenarios. Surprisingly, creating a web app in .Net Core is very similar to doing a console app; in fact we could just continue with the console program we wrote in the first post and it would work just fine, even without a 'web' section in launch.json.
Go to the Explorer icon and click on Open Folder (or File → Open Folder)
Create a Code Hello World folder
Right click under the folder in Explorer and choose Open in Command Prompt - if you have it. Some Windows versions removed this option from their context menu. If not, select Open in New Window, go to the File menu and select Open Command Prompt (as Administrator, if you can) from there
Write 'dotnet new console' in the console window, then close the command prompt and the Windows Explorer window, if you needed it
Select the newly created Code Hello World folder
From the open folder, open Program.cs
To the warning "Required assets to build and debug are missing from your project. Add them?" click Yes
To the info "There are unresolved dependencies from '<your project>.csproj'. Please execute the restore command to continue." click Restore
Click the Debug icon and press the green play arrow
Wait! Aren't these the steps for a console app? Yes they are. To turn this into a web application, we have to go through these few more steps:
Open project.json and add
,"Microsoft.AspNetCore.Server.Kestrel": "1.0.0"
to dependencies (right after Microsoft.NETCore.App)
There are a lot of warnings and errors displayed, but the program compiles and when run it keeps running until stopped. To see the result open a browser window on http://localhost:5000. Closing and reopening the folder will make the warnings go away.
#WhatHaveWeDone
So first we added Microsoft.AspNetCore.Server.Kestrel to the project. We added the Microsoft.AspNetCore namespace to the project. With this we have now access to the Microsoft.AspNetCore.Hosting which allows us to use a fluent interface to build a web host. We UseKestrel (Kestrel is based on libuv, which is a multi-platform support library with a focus on asynchronous I/O. It was primarily developed for use by Node.js, but it's also used by Luvit, Julia, pyuv, and others.) and we UseStartup with a class creatively named Startup. In that Startup class we receive an IApplicationBuilder in the Configure method, to which we attach a simple handler on Run.
In order to understand the delegate sent to the application builder we need to go through the concept of Middleware, which are components in a pipeline. In our case Run was used, because as a convention Run is the last thing to be executed in the pipeline. We could have used just as well Use without invoking the next component. Another option is to use Map, which is also a convention exposed through an extension method like Run, and which is meant to branch the pipeline.
Anyway, all of this you can read in the documentation. A must read is the Fundamentals section.
Various useful things
Let's ponder on what we would like in a real life web site. Obviously we need a web server that responds differently for different URLs, but we also need logging, security, static files. Boilerplate such as errors in the pages and not found pages need to be handled. So let's see how we can do this. Some tutorials are available on how to do that with Visual Studio, but in this post we will be doing this with Code! Instead of fully creating a web site, though, I will be adding to the basic Hello World above one or two features at a time, postponing building a fully functioning source for another blog post.
Logging
We will always need a way of knowing what our application is doing and for this we will implement a more complete Configure method in our Startup class. Instead of only accepting an IApplicationBuilder, we will also be asking for an ILoggerFactory. The main package needed for logging is
"Microsoft.Extensions.Logging": "1.0.0"
, which needs to be added to dependencies in project.json. From .NET Core 1.1, Logging is included in the Microsoft.AspNetCore package.
Here is some code:
Startup.cs
using Microsoft.AspNetCore.Builder; using Microsoft.Extensions.Logging;
So far so good, but where does the logger log? For that matter, why do I need a logger factory, can't I just instantiate my own logger and use it? The logging mechanism intended by the developers is this: you get the logger factory, you add logger providers to it, which in turn instantiate logger instances. So when the logger factory creates a logger, it actually gives you a chain of different loggers, each with their own settings.
For example, in order to log to the console, you run loggerFactory.AddConsole(); for which you need to add the package
"Microsoft.Extensions.Logging.Console": "1.0.0"
to project.json. What AddConsole does is actually factory.AddProvider(new ConsoleLoggerProvider(...));. The provider will then instantiate a ConsoleLogger for the logger chain, which will write to the console.
Additional logging options come with the Debug or EventLog or EventSource packages as you can see at the GitHub repository for Logging. Find a good tutorial on how to create your own Logger here.
Static files
It wouldn't be much of a web server if it wouldn't serve static files. ASP.Net Core has two concepts for web site roots: Web root and Content root. Web is for web-servable content files, while Content is for application content files, like views and stuff. In order to serve these we use the
Now all we have to do is add a page and some files in the www folder of our app and we have a web server. But what does UseStaticFiles do? It runs app.UseMiddleware(), which adds StaticFilesMiddleware to the middleware chain which, after some validations and checks, runs StaticFileContext.SendRangeAsync(). It is worth looking up the code of these files, since it both demystifies the magic of web servers and awes through simplicity.
Routing
Surely we need to serve static content, but what about dynamic content? Here is where routing comes into place.
First add package
"Microsoft.AspNetCore.Routing": "1.0.0"
to project.json, then add some silly routing to Startup.cs:
From .NET Core 1.1, Routing is found in the Microsoft.AspNetCore package.
Program.cs
using Microsoft.AspNetCore.Hosting;
namespace ConsoleApplication { publicclass Program { publicstaticvoid Main(string[] args) { var host = new WebHostBuilder() .UseKestrel() .UseStartup<Startup>() .Build();
host.Run(); } } }
Startup.cs
using System; using System.Threading.Tasks; using Microsoft.AspNetCore.Builder; using Microsoft.AspNetCore.Http; using Microsoft.AspNetCore.Routing; using Microsoft.Extensions.DependencyInjection;
public Task RouteAsync(RouteContext context) { var requestPath = context.HttpContext.Request.Path; if (requestPath.StartsWithSegments("/hello", StringComparison.OrdinalIgnoreCase)) { context.Handler = async c => { await c.Response.WriteAsync($"Hello world!"); }; } return Task.FromResult(0); } } } }
Some interesting things added here. First of all, we added a new method to the Startup class, called ConfigureServices, which receives an IServicesCollection. To this, we AddRouting, with a familiar by now extension method that shortcuts to adding a whole bunch of services to the collection: contraint resolvers, url encoders, route builders, routing marker services and so on. Then in Configure we UseRouter (shortcut for using a RouterMiddleware) with a custom built implementation of IRouter. What it does is look for a /hello URL request and returns the "Hello World!" string. Go on and test it by going to http://localhost:5000/hello.
Take a look at the documentation for routing for a proper example, specifically using a RouteBuilder to build an implementation of IRouter from a default handler and a list of mapped routes with their handlers and how to map routes, with parameters and constraints. Another post will handle a complete web site, but for now, let's just build a router with several routes, see how it goes:
Startup.cs
using System; using System.Threading.Tasks; using Microsoft.AspNetCore.Builder; using Microsoft.AspNetCore.Http; using Microsoft.AspNetCore.Routing; using Microsoft.Extensions.DependencyInjection;
How does that work? First of all we added a more complex HelloRouter implementation that handles a name. To the route builder we added a default handler that just displays the parameters receives, a Route instance that contains the URL template, the IRouter implementation and an inline constraint resolver for the parameter and finally we added just a mapped route that goes to the default router. That is why if no hello or package URL template are matched the site returns 404 and otherwise it chooses one handler or another and displays the result.
Error handling
Speaking of 404 code that can only be seen in the browser's developer tools, how do we display an error page? As usual, read the documentation to understand things fully, but for now we will be playing around with the routing example above and adding error handling to it.
The short answer is add some middleware to the mix. Extensions methods in
using System; using System.Threading.Tasks; using Microsoft.AspNetCore.Builder; using Microsoft.AspNetCore.Hosting; using Microsoft.AspNetCore.Http; using Microsoft.AspNetCore.Routing; using Microsoft.Extensions.DependencyInjection;
public Task RouteAsync(RouteContext context) { var name = context.RouteData.Values["name"] asstring; if (String.IsNullOrEmpty(name)) name = "World"; if (String.Equals(name, "error", StringComparison.OrdinalIgnoreCase)) { thrownew ArgumentException("Hate errors! Won't say Hi!"); }
var requestPath = context.HttpContext.Request.Path; if (requestPath.StartsWithSegments("/hello", StringComparison.OrdinalIgnoreCase)) { context.Handler = async c => { await c.Response.WriteAsync($"Hi, {name}!"); }; } return Task.FromResult(0); } } } }
The post is already too long so I won't be covering here a lot of what is needed such as security or setting the environment name so one can, for example, only show the development error page for the development environment. The VS Code ecosystem is at its beginning and work is being done to improve it as we speak. The basic concept of middleware allows us to build whatever we want, starting from scratch. In a future post I will discuss MVC and Web API and the more advanced concepts related to the web. Perhaps it will be done in VS Code as well, perhaps not, but my point is that with the knowledge so far one can control all of these things by knowing how to handle a few classes in a list of middleware. You might not need an off the shelf framework, you may write your own.
Since the release of .NET Core 1.1, a lot has changed, so I am trying to keep this up to date as much as possible, but there still might be some leftover obsolete info from earlier versions.
So .NET Core was released and I started wondering if I could go full in, ignoring the usual way to work with .NET (you know, framework, Visual Studio, ReSharper, all that wonderful jazz). Well, five minutes in and I am worried. It looks like someone is trying to sell me developing in online editors packaged in a skinny app, just so that I run away scared back to the full Visual Studio paid stack. Yet, I'm only five minutes in, so I am going to persevere.
Installation
Getting started (on Windows) involves three easy steps:
Download and install the .NET Core SDK for Windows (if you want the complete Core, that works with Visual Studio, go here for more details. This is the freeware version of getting started :) )
After running Code, press Ctrl-P and in the textbox that appears write 'ext install csharp', wait for a dropdown to appear and click on the C# for Visual Studio Code (powered by Omnisharp) entry to install support for C#
Now you understand why I am a little worried. By default, VS Code comes with built-in support for JavaScript, TypeScript and Node.js. That's it!
Visual Studio Code overview
Next stop, read up on how Code works. It's a different approach than Visual Studio. It doesn't open up projects, it opens up folders. The project, configuration, package files, even the settings files for Code itself, are json, not XML. The shortcut you used earlier is called Quick Open and is used to install stuff, find files, open things up, etc. Another useful shortcut is F1, which doesn't pop up some useless help file, but the Command Palette, which is like a dropdown for menu commands.
And, of course, as for any newly installed software, go immediately to settings and start customizing things. Open the File menu, go to Preferences and open User Settings and you will be amazed to see that instead of a nice interface for options you get two side-by-side json files. One is with the default settings and the other one is for custom settings that would override defaults. Interestingly, I see settings for Sass and Less. I didn't see anything that needed changing right from the start, so let's go further.
Another thing that you notice is the left side icon bar. It contains four icons:
Explorer - which opens up files and probably will show solutions
Search - which helps you search within files
Debug - I can only assume that it debugs stuff
Git - So Git is directly integrated in the code editor, not "source control", just Git. It is an interesting statement to see Git as a first class option in the editor, while support for C# needs to be installed.
Hello world! - by ear
A little disappointing, when you Open a Folder from Explorer, it goes directly to My Documents. I don't see a setting for the initial projects folder to open. Then again, maybe I don't need it. Navigate to where you need to, create a new folder, open it up. I named mine "Code Hello World", because I am a creative person at heart. Explorer remains open in the left, showing a list of Working Files (open files) and the folder with some useful options such as New File, New Folder, Refresh and Collapse All. Since we have opened a folder, we have access to the File → Preferences → Workspace Settings json files, which are just like the general Code settings, only applying to this one folder. Just opening the files creates a .vscode/settings.json empty file.
Let's try to write some code. I have no idea what I should write, so let's read up on it. Another surprise: not many articles on how to start a new project. Well, there is something called ASP.Net Core, which is another install, but I care not about the web right now. All I want is write a short Hello World thing. There are some pages about writing console applications with Code on Macs, but you know, when I said I am a creative person I wasn't going that far! I go to Quick Open, I go to the Command Palette, nothing resembling "new project" or "console app" or "dotnet something". The documentation is as full of information as a baby's bottom is full of hair. You know what that means, right? It's cutting edge, man! You got to figure it out yourself!
So let's go from memory, see where it gets us. I need a Program.cs file with a namespace, a Program class and a static Main method that accepts an array of strings as a first argument. I open a new file (which also gets created under the .vscode folder) and I write this:
I then go to the Debug icon and click it. It asks me to select the environment in which I will debug stuff: NodeJS, the Code extension environment and .Net Core. I choose .Net Core and another configuration file is presented to me, called launch.json. Now we are getting somewhere! Hoping it is all good - I am tired of all this Linuxy thing - I press the green Debug arrow. Oops! It appears I didn't select the Task Runner. A list of options is presented to me, from which two seem promising: MSBuild and .NET Core. Fuck MSBuild! Let's go all Core, see if it works.
Choosing .NET Core creates a new json file, this time called tasks.json, containing a link to documentation and some settings that tell me nothing. The version number for the file is encouraging: 0.1.0. Oh, remember the good old Linux days when everything was open source, undocumented, crappy and everyone was cranky if you even mentioned a version number higher or equal to 1?
I press the damn green arrow again and I get another error: the preLaunchTask "build" terminated with exit code 1. I debug anyway and it says that I have to configure launch.json program setting, with the name of the program I have to debug. BTW, launch.json has a 0.2.0 version. Yay! Looking more carefully at the launch.json file I see that the name of the program ends with .dll. I want an .exe, yet changing the extension is not the only thing that I need to do. Obviously I need to make my program compile first.
I press Ctrl-P and type > (the same thing can be achieved by Ctrl-Shift-P or going to the menu and choosing Command Palette) and look for Build and I find Tasks: Run Build Task. It even has the familiar Ctrl-Shift-B shortcut. Maybe that will tell me more? It does nothing. Something rotates in the status bar, but no obvious result. And then I remember the good old trusty Output window! I go to View and select Toggle Output. Now I can finally see what went wrong. Can you guess it? Another json file. This time called project.json and having the obvious problem that it doesn't exist. Just for the fun of it I create an empty json file and it still says it doesn't exist.
What now? I obviously have the same problem as when I started: I have no idea how to create a project. Armed with a little bit more information, I go browse the web again. I find the documentation page for project.json, which doesn't help much because it doesn't have a sample file, but also, finally a tutorial that make sense: Console Application. And here I find that I should have first run the command line dotnet new console in the folder I created, then open the project with VS Code.
Hello world! - by tutorial
Reset! Close Code, delete everything from the folder. Also, make sure - if you run a file manager or some other app and you just installed .NET Core - that you have C:\Program Files\dotnet\ in the PATH. Funny thing: the prompt for deleting some files from Code is asking whether to send them to Recycle Bin. I have Recycled Bin disabled, so it fails and then presents you with the option to delete them permanently.
Now, armed with knowledge I go to the folder Code Hello World, run the command 'dotnet new console' ("console" is the name of the project template. Version 1.0 allowed you to omit the template and it would default to console. From version 1.1 you need to specify it explicitly) and it creates a project.json .csproj file (with the name of the folder you were in) and a Program.cs file that is identical to mine, if you count the extra using System line. I run 'dotnet restore', 'dotnet build' and I notice that obj and bin folders have been created. The output, though, is not an exe file, but a dll file. 'dotnet run' actually runs as it should and displays "Hello, World!".
Let's open it with Code. I get a "Required assets to build and debug are missing from your project. Add them?" and I say Yes, which creates the .vscode folder, containing launch.json and tasks.json. Ctrl-Shift-B pressed and I get "Compilation succeeded." Is it possible that now I could press F5 and see the program run? No, of course not, because I must "set up the launch configuration file for my application". What does it mean? Well, apparently if I go to the Debug icon and press the green arrow icon (that has the keyboard shortcut F5) the program does run. I need to press the button for the Debug Console that is at the top of the Debug panel to see the result, but it works. From then on, pressing F5 works, too, no matter where I am.
Unconvinced by the whole thing, I decide to do things again, but this time do as little as possible from the console.
Hello world! - by Code
Reset! Delete the folder entirely and restart Visual Studio code. Then proceed with the following steps:
Go to the Explorer icon and click on Open Folder (or File → Open Folder)
Create a Code Hello World folder
Right click under the folder in Explorer and choose Open in Command Prompt - if you have it. Some Windows versions removed this option from their context menu. If not, select Open in New Window, go to the File menu and select Open Command Prompt (as Administrator, if you can) from there
Write 'dotnet new console' in the console window, then close the command prompt and the Windows Explorer window, if you needed it
Select the newly created Code Hello World folder
From the open folder, open Program.cs
To the warning "Required assets to build and debug are missing from your project. Add them?" click Yes
To the info "There are unresolved dependencies from '<your project>.csproj'. Please execute the restore command to continue." click Restore
Click the Debug icon and press the green play arrow
That's it!
But let's discuss one poignantly ridiculous part of the step list. Why did we have to open and close the folder? It is in order to get that prompt to add required assets. If you try to run the app without doing that, Code will create a generic launch.json file with placeholders instead of actual folder names. Instead of
and a warning telling you to configure launch.json. It only works after changing the program property to '/bin/Debug/netcoreapp1.0/Code Hello World.dll' and, of course, the web and attach configuration sections are pointless.
Debugging
I placed a breakpoint on Console.WriteLine. The only declared variable is the args string array. I can see it in Watch (after adding it by pressing +) or in the Locals panel, I can change it from the Debug Console. I can step through code, I can set a condition on the breakpoint. Nothing untoward here. There is no Intellisense in the Debug Console, though.
In order to give parameters to the application in debug you need to change the args property of launch.json. Instead of args:[], something like args:["test",test2"]. In order to run the application from the command line you need to run it with dotnet, like this: dotnet "Code Hello World.dll" test test2.
Conclusion
.Net Code is not nearly ready as a comfortable IDE, but it's getting there, if enough effort will be put into it. It seems to embrace concepts from both the Windows and Linux world and I am worried that it may gain traction with neither. I am yet to try to build a serious project though and next on the agenda is trying an ASP.Net Core application, maybe a basic API.
While I am not blown away by what I have seen, I declare myself intrigued. If creating extensions for Code is easy enough, I may find myself writing my own code editor tools. Wouldn't that be fun? Stay tuned for more!
Just when I thought I don't have anything else to add, I found new stuff for my Chrome browser extension. Bookmark Explorer now features:
configurable interval for keeping a page open before bookmarking it for Read Later (so that all redirects and icons are loaded correctly)
configurable interval after which deleted bookmarks are no longer remembered
remembering deleted bookmarks no matter what deletes them
more Read Later folders: configure their number and names
redesigned options page
more notifications on what is going on
The extension most resembles OneTab, in the sense that it is also designed to save you from opening a zillion tabs at the same time, but differs a lot by its ease of use, configurability and the absolute lack of any connection to outside servers: everything is stored in Chrome bookmarks and local storage.
The Date object in Javascript is not a primitive, it is a full fledged object, with a constructor and various instances, with methods that mutate their values. That means that the meaning of equality between two dates is ambiguous: what does it mean that date1 equals date2? That they are the same object or that they point to the same instance in time? In Javascript, it means they are the same object. Let me give you some code:
var date1=new Date(); var date2=new Date(date1.getTime()); // now date2 points to the same moment in time as date1 console.log(date1==date2) // outputs "false" date1=date2; console.log(date1==date2) // outputs "true", date1 and date2 are pointing to the same object
So, how can we compare two dates? First thought it to turn them into numeric values (how many milliseconds from the beginning of 1970) and compare them. Which works, but looks ugly. Instead of using date1.getTime() == date2.getTime() one might use the fact that the valueOf function of the Date object also returns the same numeric value as getTime and turn the comparison into a substraction instead. To compare the two dates, just check if date2 - date1 == 0.
I was working on a project of mine that also has some unit tests. In one of them, the HTML structure is abstracted and sent as a jQuery created element to a page script. However, the script uses the custom jQuery selector :visible, which completely fails in this case. You see, none of the elements are visible unless added to the DOM of a page. The original jQuery selector goes directly to existing browser methods to check for visibility:
jQuery.expr.filters.visible = function( elem ) {
// Support: Opera <= 12.12 // Opera reports offsetWidths and offsetHeights less than zero on some elements // Use OR instead of AND as the element is not visible if either is true // See tickets #10406 and #13132 return elem.offsetWidth > 0 || elem.offsetHeight > 0 || elem.getClientRects().length > 0; };
So I've decided to write my own simple selector which replaces it. Here it is:
$.extend($.expr[':'], { nothidden : function (el) { el=$(el); while (el.length) { if (el[0].ownerDocument===null) break; if (el.css('display')=='none') returnfalse; el=el.parent(); } returntrue; } });
It goes from the selected element to its parent, recursively, until it doesn't find anything or finds some parent which is with display none. I was only interested in the CSS display property, so if you want extra stuff like visibility or opacity, change it yourself. What I wanted to talk about was that strange ownerDocument property check. It all stems from a quirk in jQuery which causes $(document).css(...) to fail. The team decided to ignore the bug report regarding it. But, the question is, what happens when I create an element with jQuery and don't attach it to the DOM? Well, behind the scene, all elements are being created with document.createElement or document.createDocumentFragment which, it makes sense, fill the ownerDocument property with the document object that created the element. The only link in the chain that doesn't have an ownerDocument is the document itself. You might want to remember this in case you want to go up the .parent() ladder yourself.
Now, warning: I just wrote this and it might fail in some weird document in document cases, like IFRAMEs and stuff like that. I have not tested it except my use case, which luckily involves only one type of browser.
Bookmark Explorer, a Chrome browser extension that allows you to navigate inside bookmark folders on the same page, saving you from a deluge of browser tabs, has now reached version 2.4.0. I consider it stable, as I have no new features planned for it and the only changes I envision in the near future is switching to ECMAScript 6 and updating the unit test (in other words, nothing that concerns the user).
Let me remind you of its features:
lets you go to the previous/next page in a bookmark folder, allowing sequential reading of selected news or research items
has context menu, popup buttons and keyboard shortcut support
shows a page with all the items in the current bookmark folder, allowing selection, deletion, importing/exporting of simple URL lists
shows a page with all the bookmarks that were deleted, allowing restoring them, clearing them, etc.
keyboard support for both pages
notifies you if the current page has been bookmarked multiple times
no communication with the Internet, it works just as well offline - assuming the links would work offline, like local files
For a very long time the only commonly used expression of software was the desktop application. Whether it was a console Linux thing or a full blown Windows application, it was something that you opened to get things done. In case you wanted to do several things, you either opted for a more complex application or used several of them, usually transferring partial work via the file system, sometimes in more obscure ways. For example you want to publish a photo album, you take all pictures you've taken, process them with an image processing software, then you save them and load them with a photo album application. For all intents and purposes, the applications are black boxes to each other, they only connect with inputs and outputs and need not know what goes on inside one another.
Enter the web and its novel concept of URLs, Uniform Resource Locators. In theory, everything on the web can be accessible from the outside. You want to link to a page, you have its URL to add as an anchor in your page and boom! A web site references specific resources from another. The development paradigm for these new things was completely different from big monolithic applications. Sites are called sites because they should be a place for resources to sit in; they are places, they have no other role. The resources, on the other hand, can be processed and handled by specific applications like browsers. If a browser is implemented in all operating systems in the same way, then the resources get accessed the same way, making the operating system - the most important part of one's software platform - meaningless. This gets us to this day and age when an OS is there to restrict what you can do, rather than provide you with features. But that's another story altogether.
With increased computing power, storage space, network speeds and the introduction and refining of Javascript - now considered a top contender for the most important programming language ever - we are now able to embed all kinds of crazy features in web pages, so much so that we have reached a time when writing a single page application is not only possible, but a norm. They had to add new functionality to browsers in order to let the page tweak the browser address without reloading the page and that is a big deal! And a really dumb one. Let me explain why.
The original concept was that the web would own the underlying mechanism of resource location. The new concept forces the developer to define what a resource locator means. I can pretty much make my own natural language processing system and have URLs that look like: https://siderite.com/give me that post ranting about the single page apps. And yes, the concept is not new, but the problem is that the implementation is owned by me. I can change it at any time and, since it all started from a desire to implement the newest fashion, destined to change. The result is chaos and that is presuming that the software developer thought of all contingencies and the URL system is adequate to link to resources from this page... which is never true. If the developer is responsible for interpreting what a URL means, then it is hardly "uniform".
Another thing that single page apps lead to is web site bloating. Not only do you have to load the stuff that now is on every popular website, like large pointless images and big fonts and large empty spaces, but also the underlying mechanism of the web app, which tells us where we are, what we can do, what gets loaded etc. And that's extra baggage that no one asked for. A single page app is hard to parse by a machine - and I don't care about SEO here, it's all about the way information is accessible.
My contention is that we are going backwards. We got the to point where connectivity is more important than functionality, where being on the web is more important than having complex well done features in a desktop app. It forced us to open up everything: resources, communication, protocols, even the development process and the code. And now we are going back to the "one app to rule them all" concept. And I do understand the attraction. How many times did I dream of adding mini games on my blog or make a 3D interface and a circular corner menu and so on. This things are cool! But they are only useful in the context of an existing web page that has value without them. Go to single page websites and try to open them with Javascript disabled. Google has a nice search page that works even then and you know what? The same page with Javascript is six times larger than the one without - and this without large differences in display. Yes, I know that this blog has a lot of stuff loaded with Javascript and that this page probably is much smaller without it, but the point it that the blog is still usable. For more on this you should take the time to read The Web Obesity Crisis, which is not only terribly true, but immensely funny.
And I also have to say I understand why some sites need to be single page applications, and that is because they are more application than web site. The functionality trumps the content. You can't have an online image processing app work without Javascript, that's insane. You don't need to reference the resource found in a color panel inside the photo editor, you don't need to link to the image used in the color picker and so on. But web sites like Flipboard, for example, that display a blank page when seen without Javascript, are supposed to be news aggregators. You go there to read stuff! It is true we can now decide how much of our page is a site and how much an application, but that doesn't mean we should construct abominations that are neither!
A while ago I wrote another ranty rant about how taking over another intuitively common web mechanism: scrolling, is helping no one. These two patterns are going hand in hand and slowly polluting the Internet. Last week Ars Technica announced a change in their design and at the same time implemented it. They removed the way news were read by many users: sequentially, one after the other, by scrolling down and clicking on the one you liked, and resorted to a magazine format where news were just side by side on a big white page with large design placeholders that looked cool yet did nothing but occupy space and display the number of comments for each. Content took a backseat to commentary. I am glad to report that two days later they reverted their decision, in view of the many negative comments.
I have nothing but respect for web designers, as I usually do for people that do things I am incapable of, however their role should always be to support the purpose of the site. Once things look cool just for the sake of it, you get Apple: a short lived bloom of user friendliness, followed by a vomitous explosion of marketing and pricing, leading to the immediate creation of cheaper clones. Copying a design because you think is great is normal, copying a bunch of designs because you have no idea what your web page is supposed to do is just direct proof you are clueless, and copying a design because everyone else is doing it is just blindly following clueless people.
My advice, as misguided as it could be, is forget about responsiveness and finger sized checkboxes, big images, crisp design and bootstrapped pages and all that crap. Just stop! And think! What are you trying to achieve? And then do it, as a web site, with pages, links and all that old fashioned logic. And if you still need cool design, add it after.
Update 17 June 2016: I've changed the focus of the extension to simply change the aspect of stories based on status, so that stories with content are highlighted over simple shares. I am currently working on another extension that is more adaptive, but it will be branded differently.
Update 27 May 2016: I've published the very early draft of the extension because it already does a cool thing: putting original content in the foreground and shrinking the reposts and photo uploads and feeling sharing and all that. You may find and install the extension here.
Have you ever wanted to decrease the spam in your Facebook page but couldn't do it in any way that would not make you miss important posts? I mean, even if you categorize all your contacts into good friends, close friends, relatives, acquaintances, then you unfollow the ones that really spam too much and you hide all posts that you don't like, you have no control over how Facebook decides to order what you see on the page. Worse than that, try to refresh repeatedly your Facebook page and see wildly oscillating results: posts appear, disappear, reorder themselves. It's a mess.
Well, true to this and my word I have started work on a Chrome extension to help me with this. My plan is pretty complicated, so before I publish the extension on the Chrome Webstore, like I did with my previous two efforts, I will publish this on GitHub while I am still working on it. So, depending on where I am, this might be alpha, beta or stable. At the moment of this writing - first commit - alpha is a pretty big word.
Here is the plan for the extension:
Detect the user has opened the Facebook page
Inject jQuery and extension code into the page
Detect any post as it appears on the page
Extract as many features as possible
Allow the user to create categories for posts
Allow the user to drag posts into categories or out of them
Use AI to determine the category a post most likely belongs to
Alternatively, let the user create their own filters, a la Outlook
Show a list of categories (as tabs, perhaps) and hide all posts under the respective categories
This way, one might skip the annoying posts, based on personal preferences, while still enjoying the interesting ones. At the time of this writing, the first draft, the extension only works on https://www.facebook.com, not on any subpages, it extracts the type of the post and sets a CSS class on it. It also injects a CSS which makes posts get dimmer and smaller based on category. Mouse over to get the normal size and opacity.
How to make it work for you:
In Chrome, go to Manage Extensions (chrome://extensions/)
Click on the Developer Mode checkbox
Click on the Load unpacked extension... button
Select a folder where you have downloaded the source of this extension
Open a new tab and load Facebook there
You should see the posts getting smaller and dimmer based on category.
Change statusProcessor.css to select your own preferences (you may hide posts altogether or change the background color, etc).
As usual, please let me know what you think and contribute with code and ideas.
I've written another Chrome extension that I consider in beta, but so far it works. Really ugly makeshift code, but I am not gathering data about the way I will use it, then I am going to refactor it, just as I did with Bookmark Explorer. You may find the code at GitHub and the extension at the Chrome webstore.
This is how it works: Every time you access anything with the browser, the extension will remember the IPs for any given host. It will hold a list of the IPs, in reverse order (last one first), that you can just copy and paste into your hosts file. The hosts file is found in c:/Windows/System32/drivers/etc/hosts and on Linux in /etc/hosts. Once you add a line in the format "IP host" in it, the computer will resolve the host with the provided IP. Every time there is a problem with DNS resolution, the extension will add the latest known IP into the hosts text. Since the extension doesn't have access to your hard drive, you need to edit the file yourself. The icon of DNS resolver will show the number of hosts that it wants to resolve locally or nothing, if everything is OK.
The extension allows manual selection of an IP for a host and forced inclusion or exclusion from the list of IP/host lines. Data can be erased (all at once for now) as well. The extension does not communicate with the outside, but it does store a list of all domains you visit, so it is a slight privacy risk - although if someone has access to the local store of a browser extension, it's already too late. There is also the possibility of the extension to replace the host with IP directly in the browser requests, but this only works for the browser and fails in case the host name is important, as in the case of multiple servers using the same IP, so I don't recommend using it.
There are two scenarios for which this extension is very useful:
The DNS server fails for some reason or gives you a wrong IP
Someone removed the IP address from DNS servers or replaced it with one of their own, like in the case of governments censorship
I have some ideas for the future:
Sharing of working IP/host pairs - have to think of privacy before that, though
Installing a local DNS server that can communicate locally with the extension, so no more hosts editing - have to research and create one
Upvoting/Downvoting/flagging shared pairs - with all the horrible head-ache this comes with
As usual, let me know what you think here, or open issues on GitHub.
I have started writing Chrome extensions, mainly to address issues that my browser is not solving, like opening dozens of tabs and lately DNS errors/blocking and ad blocking. My code writing process is chaotic at first, just writing stuff and changing it until things work, until I get to something I feel is stable. Then I feel the need to refactor the code, organizing and cleaning it and, why not, unit testing it. This opens the question on how to do that in Javascript and, even if I have known once, I needed to refresh my understanding with new work. Without further ado: QUnit, a Javascript testing framework. Not that all code here will be in ES5 or earlier, mainly because I have not studied ES6 and I want this to work with most Javascript.
QUnit
QUnit is something that has withstood the test of time. It was first launched in 2008, but even now it is easy to use with simple design and clear documentation. Don't worry, you can use it even without jQuery. In order to use it, create an HTML page that links to the Javascript and CSS files from QUnit, then create your own Javascript file containing the tests and add it to the page together with whatever you are testing.
Already this raises the issue of having Javascript code that can be safely embedded in a random web page, so consider how you may encapsulate the code. Other testing frameworks could run the code in a headless Javascript engine, so if you want to be as generic as possible, also remove all dependencies on an existing web page. The oldest and simplest way of doing this is to use the fact that an orphan function in Javascript has its own scope and always has this pointing to the global object - in case of a web page, this would be window. So instead of something like:
i=0; while (i<+(document.getElementById('inpNumber').value)) { i++; // do something }
do something like this:
(function() {
var global=this;
var i=0; while (i<+(global.document.getElementById('inpNumber').value)) { i++; // do something }
})();
It's a silly example, but it does several things:
It keeps variable i in the scope of the anonymous function, thus keeping it from interfering with other code on the page
It clearly defines a global object, which in case of a web page is window, but may be something else
It uses global to access any out of scope values
In this particular case, there is still a dependency on the default global object, but if instead one would pass the object somehow, it could be abstracted and the only change to the code would be the part where global is defined and acquired.
Let's start with QUnit. Here is a Hello World kind of thing:
QUnit.test("Hello World", function (assert) { assert.equal(1+1, 2, "One plus one is two"); });
We put it in 'tests.js' and include it into a web page that looks like this:
As you can see, we declare a test with the static QUnit.test function, which receives a name and a function as parameters. Within the function, the assert object will do everything we need, mainly checking to see if a result conforms to an expected value or a block throws an exception. I will not go through a detailed explanation on simple uses like that. If you are interested peruse the QUnit site for tutorials.
Modules
What I want to talk about are slightly more advanced scenarios. The first thing I want to address is the concept of modules. If we declare all the tests, regardless on how many scripts they are arranged in, the test page will just list them one after another, in a huge blob. In order to somehow separate them in regions, we need a module. Here is another example:
QUnit.module("Addition"); QUnit.test("One plus one", function (assert) { assert.equal(1+1, 2, "One plus one is two"); }); QUnit.module("Multiplication"); QUnit.test("Two by two", function (assert) { assert.equal(2*2, 4, "Two by two is four"); });
resulting in:
It may look the same, but a Module: dropdown appeared, allowing one to choose which module to test or visualize. The names of the tests also includes the module name. Unfortunately, the resulting HTML doesn't have containers for modules, something one can collapse or expand at will. That is too bad, but it can be easily fixed - this is not the scope of the post, though. A good strategy is just to put all related tests in the same Javascript file and use QUnit.module as the first line.
Asynchronicity
Another interesting issue is asynchronous testing. If we want to test functions that return asynchronously, like setTimeout or ajax calls or Promises, then we need to use assert.async. Here is an example:
QUnit.config.testTimeout = 1000; QUnit.module("Asynchronous tests"); QUnit.test("Called after 100 milliseconds", function (assert) { var a=assert.async(); setTimeout(function() { assert.ok(true, "Assertion was called from setTimeout"); a(); }); },100);
First of all, we needed to declare that we expect a result asynchronously, therefore we call assert.async() and hold a reference to the result. The result is actually a function. After we make all the assertions on the result, we call that function in order to finish the test. I've added a line before the test, though, which sets the testTimeoutconfiguration value. Without it, an async test that fails would freeze the test suite indefinitely. You can easily test this by setting testTimeout to less than the setTimeout duration.
Asynchronous tests raise several questions, though. The example above is all nice and easy, but what about cases when the test is more complex, with multiple asynchronous code blocks that follow each other, like a Promise chain? What if the assertions themselves need to be called asynchronously, like when checking for the outcome of a click handler? If you run jQuery(selector).click() an immediately following assertion would fail, since the click handler is executed in another context, for example. One can imagine code like this, but look how ugly it is:
In order to solve at least this arrow antipattern I've created a stringFunctions function that looks like this:
function stringFunctions() { if (!arguments.length) throw'needs functions as parameters'; var f = function () {}; var args = arguments; for (var i = args.length - 1; i >= 0; i--) { (function () { var x = i; var func = args[x]; if (typeof(func) != 'function') throw'parameter ' + x + ' is not a function'; var prev = f; f = function () { setTimeout(function () { func(); prev(); }, 100); }; })(); }; f(); };
which makes the previous code look like this:
QUnit.test("Called after 500 milliseconds", function (assert) { var a = assert.async(); stringFunctions(function () { assert.ok(true, "First setTimeout"); }, function () { assert.ok(true, "Second setTimeout"); }, function () { assert.ok(true, "Third setTimeout"); }, function () { assert.ok(true, "Fourth setTimeout"); }, a); setTimeout(function () { assert.notOk(true, "Test timed out"); }, 500) });
Of course, this is a specific case, but at least in a very common scenario - the one when the results of event handlers are checked - stringFunctions with 1ms instead of 100ms is very useful. Click on a button, see if a checkbox is available, check the checkbox, see if the value in a span has changed, stuff like that.
Testing average jQuery web code
Another thing I want to address is how to test Javascript that is intended as a web page companion script, with jQuery manipulations of the DOM and event listeners and all that. Ideally, all this would be stored in some sort of object that is instantiated with parameters that specify the test context, the various mocks and so on and so on. Since it is not an ideal world, I want to show you a way to test a typical such script, one that executes a function at DOMReady and does everything in it. Here is an example:
which has certain advantages. First, it makes you aware of all the uses of jQuery in the code, yet it doesn't force you to declare everything in an object and having to refactor everything. Funny how you need to refactor the code in order to write unit tests in order to be able to refactor the code. Automated testing gets like that. It also solves some problems with testing Javascript offline - directly from the file system, because all you need to do now is define the testContext then load the script by creating a tag in the testing page and setting the src attribute:
var script = document.createElement('script'); script.onload = function () { // your assertions here }; script.src = "http://whatever.com/the/script.js"; document.getElementsByTagName('head')[0].appendChild(script);
In this case, even if you are running the page from the filesystem, the script will be loaded and executed correctly. Another, more elegant solution would load the script as a string and execute it inside a closure where jQuery was replaced with something that uses a mock document by default. This means you don't have to change your code at all, but you need to be able to read the script as a text, which is impossible on the filesystem. Some really messy script tag creation would be needed
QUnit.test("jQuery script Tests", function (assert) {
var global = (function () { returnthis; })();
function setIsolatedJquery() { global.originalJquery = jQuery.noConflict(true); var tc = global.testContext.document; global.jQuery = global.$ = function (selectorOrHtmlOrFunction, context) { if (typeof(selectorOrHtmlOrFunction) == 'function') return global.originalJquery.apply(this, arguments); var newContext; if (!context) { newContext = tc; //if not specified, use the testContext } else { if (typeof(context) == 'string') { newContext = global.originalJquery(context, tc); //if context is a selector, use it inside the testContext } else { newContext = context; // use the one provided } } return global.originalJquery(selectorOrHtmlOrFunction, newContext) } }; function restoreJquery() { global.jQuery = global.$ = global.originalJquery; delete global.originalJquery; }
There you have it: an asynchronous test that replaces jQuery with something with an isolated context, loads a script dynamically, performs a click in the isolated context, checks the results. Notice the generic way in which to get the value of the global object in Javascript.
Bottom-Up or Top-Bottom approach
A last point I want to make is more theoretical. After some consultation with a colleague, I've finally cleared up some confusion I had about the direction of automated tests. You see, once you have the code - or even in TDD, I guess, you know what every small piece of code does and also the final requirements of the product. Where should you start in order to create automated tests?
One solution is to start from the bottom and check that your methods call everything they need to call in the mocked dependencies. If you method calls 'chrome.tabs.create' and you have mocked chrome, your tabs.create method should count how many times it is called and your assertion should check that the count is 1. It has the advantage of being straightforward, but also tests details that might be irrelevant. One might refactor the method to call some other API and then the test would fail, as it tested the actual implementation details, not a result. Of course, methods that return the same result for the same input values - sometimes called immutable - are perfect for this type of testing.
Another solution is to start from the requirements and test that the entire codebase does what it is supposed to do. This makes more sense, but the combination of possible test cases increases exponentially and it is difficult to spot where the problem lies if a test fails. This would be called acceptance testing.
Well, the answer is: both! It all depends on your budget, of course, as you need to take into consideration not only the writing of the tests, but their maintenance as well. Automated acceptance tests would not need to change a lot, only when requirements change, while unit tests would need to be changed whenever the implementation is altered or new code is added.
Conclusion
I am not an expert on unit testing, so what I have written here describes my own experiments. Please let me know if you have anything to add or to comment. My personal opinion on the matter is that testing provides a measure of confidence that minimizes the stress of introducing changes or refactoring code. It also forces people to think in terms of "how will I test this?" while writing code, which I think is great from the viewpoint of separation of concerns and code modularity. On the other hand it adds a relatively large resource drain, both in writing and (especially) in maintaining the tests. There is also a circular kind of issue where someone needs to test the tests. Psychologically, I also believe automated testing only works for certain people. Chaotic asses like myself like to experiment a lot, which makes testing a drag. I don't even know what I want to achieve and someone tries to push testing down my throat. Later on, though, tests would be welcome, if only my manager allows the time for it. So it is, as always, a matter of logistics.
More info about unit testing with QUnit on their page.
I have been a professional in the IT business for a lot of years, less if you consider just software development, more if you count that my favorite activity since I was a kid was to mess with a computer or another. I think I know how to develop software, especially since I've kind of built my career on trying new places and new methods for doing that. And now people come to me and ask me: "Can I learn too? Can you teach me?". And the immediate answer is yes and no (heh! Learnt from the best politicians that line) Well, yes because I believe anyone who actually wants to learn can and no because I am a lousy teacher. But wait a minute... can't I become one?
You may think that it is easy to remember how it was when I was a code virgin, when I was writing Basic programs in a notebook in the hope that some day my father will buy me a computer, but it's not. My brain has picked up so many things that now they are applied automatically. I may not know what I know, but I know a lot and I am using it at all times. A few weeks ago I started thinking about these things and one of the first ideas that came to me was FizzBuzz! A program that allegedly people who can't program simple can't... err... program. Well, I thought, how would I write this best? How about worst? I even asked my wife and she gave me an idea that had never occurred to me, like not using the modulo function to determine divisibility.
And it dawned on me. To know if your code is good you need to know exactly what that code has to do. In other words, you can't program without having an idea on how to use or test it afterwards. You have to think about all the other people that would be stumbling unto your masterwork: other developers, for example, hired after you left the company, need to understand what they are looking at. You need to provide up to date and clear documentation to your users, as well. You need to handle all kinds of weird situations that your software might be subjected to. To sum it up: as a good developer you need to be a bit of all the people on the chain - users, testers, documenters, managers, marketers, colleagues - and to see the future as well. After all, you're an expert.
Of course, sketches like the one above are nothing but caricatures of people from the viewpoint of other people who don't understand them. After all, good managers need to be a little of everything as well. If you think about it, to be good at anything means you have to understand a little of everybody you work with and do your part well - exactly the opposite of specialization, the solution touted as solving every problem in the modern world. Anyway, enough philosophy. We were talking programming here.
What I mean to say is that for every bit of our craft, we developers are doing good things for other people. We code so that the computer does the job well, but we are telling it to do things that users need, we write concisely yet clear so that other developers can work from where we leave off, we write unit tests to make sure what we do is what we mean and ease the work of people who need to manually check that, we comment the code so that anyone can understand at a glance what a method does and maybe even automate the creation of documents explaining what the software does. And we draw lines in a form of a kitten so that marketers and managers sell the software - and we hate it, but we do it anyway.
So I ask, do we need to learn to write programs all over again? Because, to be frank, coders today write in TDD style because they think it's cutting edge, not that they are doing it for someone; they work in agile teams not because they know everybody will get a better understanding of what they are doing and prevent catastrophic crashes caused by lack of vision, but because they feel it takes managers off their backs and they can do their jobs; they don't write comments for the documentation team, but because they fear their small attention span might make them forget what the hell they were doing; they don't write several smaller methods instead of a large one because they believe in helping others read their code, but because some new gimmick tells them they have too much cyclomatic complexity. And so on and so on.
What if we would learn (and teach) that writing software is nothing but an abstraction layer thrown over helping all kinds of people in need and that even the least rockstar ninja superhero developer is still a hero if they do their job right? What if being a good cog in the machine is not such a bad thing?
While writing this I went all over the place, I know, and I didn't even touch what started me thinking about it: politics and laws. I was thinking that if we define the purpose of a law when we write it and package them together, anyone who can demonstrate that the effect is not the desired one can remove the law. How grand would that be? To know that something is applied upon you because no one could demonstrate that it is bad or wrong or ineffective.
We do that in software all the time, open software, for example, but also the internal processes in a programming shop designed to catch flaws early and to ensure people wrote things how they should have. Sometimes I feel so far removed from "the real world" because what I am doing seems to make more sense and in fact be more real than the crap I see all around me or on the media. What if we could apply this everywhere? Where people would take responsibility individually, not in social crowds? Where things would be working well not because a lot of people agree, but because no one can demonstrate they are working bad? What if the world is a big machine and we need to code for it?
Maybe learning to code is learning to live! Who wouldn't want to teach that?
During one revamp of the blog I realized that I didn't have images for some of my posts. I had counted pretty much on the Blogger system that provides a post.thumbnailUrl post metadata that I can use in the display of the post, but the url is not always there. Of course if you have a nice image in the post somewhere prominently displayed, the thumbnail URL will be populated, but what if you have a video? Surprisingly, Blogger has a pretty shitty video to thumbnail mechanism that prompted me to build my own.
So the requirements would be: get me the image representing a video embedded in my page, using Javascript only.
Well, first of all, videos can be actual video tags, but most of the time they are iframe elements coming from a reliable global provider like YouTube, Dailymotion, Vimeo, etc, and all the information available is the URL of the display frame. Here is the way to get the thumbnail for these scenarios:
YouTube
Given the iframe src value:
// find youtube.com/embed/[videohash] or youtube.com/embed/video/[videohash] var m = /youtube\.com\/embed(?:\/video)?\/([^\/\?]+)/.exec(src); if (m) { // the thumbnail url is https://img.youtube.com/vi/[videohash]/0.jpg imgSrc = 'https://img.youtube.com/vi/' + m[1] + '/0.jpg'; }
If you have embeds in the old object format, it is best to replace them with the iframe one. If you can't change the content, it remains your job to create the code to give you the thumbnail image.
Dailymotion
Given the iframe src value:
//find dailymotion.com/embed/video/[videohash] var m=/dailymotion\.com\/embed\/video\/([^\/\?]+)/.exec(src); if (m) { // the thumbnail url is at the same URL with `thumbnail` replacing `embed` imgSrc=src.replace('embed','thumbnail'); }
Vimeo
Vimeo doesn't have a one URL thumbnail format that I am aware of, but they have a Javascript accessible API.
// find vimeo.com/video/[videohash] m=/vimeo\.com\/video\/([^\/\?]+)/.exec(src); if (m) { // set the value to the videohash initially imgSrc=m[1]; $.ajax({ //call the API video/[videohash].json url:'https://vimeo.com/api/v2/video/'+m[1]+'.json', method:'GET', success: function(data) { if (data&&data.length) { // and with the data replace the initial value with the thumbnail_medium value replaceUrl(data[0].thumbnail_medium,m[1]); } } }); }
In this example, the replaceUrl function would look for img elements to which the videohash value is attached and replace the url with the correct one, asynchronously.
TED
I am proud to announce that I was the one pestering them to make their API available over Javascript.
// find ted.com/talks/[video title].html m=/ted\.com\/talks\/(.*)\.html/.exec(src); if (m) { // associate the video title with the image element imgSrc=m[1]; $.ajax({ // call the oembed.json?url=frame_url url:'https://www.ted.com/services/v1/oembed.json?url='+encodeURIComponent(src), method:'GET', success: function(data) { // set the value of the image element asynchronously replaceUrl(removeSchemeForHttpsEnabledSites(data.thumbnail_url),m[1]); } }); returnfalse; }
video tags
Of course there is no API to get the image from an arbitrary video URL, but the standard for the video tag specifies a poster attribute that can describe the static image associated with a video.
// if the element is a video with a poster value if ($(this).is('video[poster]')) { // use it imgSrc=$(this).attr('poster'); }
 A friend of mine has been employed to write code in the new Microsoft cross-platform ASP.Net Mvc Core and one day he asked be about the difference between the [Required] and the [BindRequired] attributes. Not being an expert in ASP.Net MVC and even less in the Core version, I had no idea so I went exploring.
A friend of mine has been employed to write code in the new Microsoft cross-platform ASP.Net Mvc Core and one day he asked be about the difference between the [Required] and the [BindRequired] attributes. Not being an expert in ASP.Net MVC and even less in the Core version, I had no idea so I went exploring.
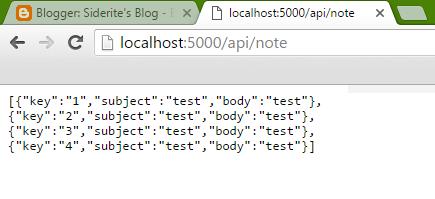
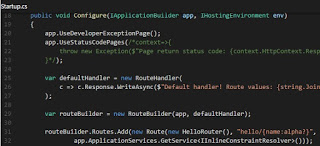
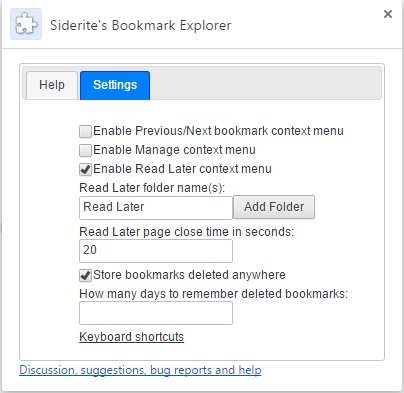
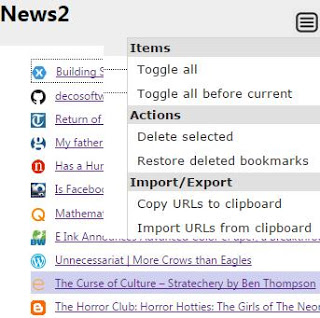

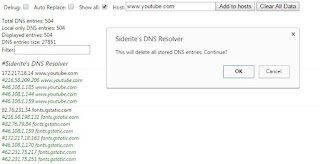



{kind=link}