Long story short: I thought FOSDEM 2016 was terribly non-technical.
The entire conference took place at the ULB Solbosch Campus in Brussels, Belgium, which is composed of several buildings in which many rooms are being used for presentations. That meant that not only you had to plan the speeches that you wanted to attend to, but also consider the time it took to move from one building to another (in the cold and rain). Add to this the fact that the space was still insufficient for most talks, and if you didn't get there before the talk started, it wasn't uncommon to find the room full and be turned down at the door for security reasons (meaning fire hazards and the likes, not stupid terrorism). I thought the mobile app FOSDEM Companion was very helpful in keeping track of what is what and where and when.
The talks themselves, though, were mostly 20-25 minutes long. While some reached to 45 minutes, most of them were short presentations of one product or another. Someone would speak in front of a Powerpoint (or some alternative) slide and the most common template was: "I am X I work at Y and we are doing product Z. Here is a history of the product, here is what it can do for you and you can find more at these links." They were open source and free, alright, but other than that it felt like it was a marketing conference, not a technical one. I have seen only one presentation that included actual code.
This doesn't mean I didn't enjoy myself. I've met old friends and some of the presentations were really interesting. I was particularly impressed by something called Ring, which is a completely peer to peer and securely encrypted communication system. Basically it allows you to find people, talk to them (via text, sound, video), while having no central server. It was something that I was looking for and that uses DHT as a discovery mechanism.
So my conclusion is that if you are not there for a specific project or topic, so that you end up finding the people that are interested in the same thing and network with them, FOSDEM is pretty superficial. The talks were recorded and the videos will slowly appear on the FOSDEM video archive site, so actually going there just to see the presentations alone might not be necessary. Being from a slightly different technical domain, I wasn't interested in socialization, and I think that was my biggest mistake.
The people there looked interesting. A friend of mine summarized it well: "one of the few places where there is a queue at the men's bathrooms and not at the women's". There were of course plenty of facially haired, pony-tailed, black leather wearing, Linux laptop carrying hackers running around, but most of the people there didn't look that young or that "hacky". In fact, I think the age average was probably around 40.
That's about it for my FOSDEM report. If you need any more information, leave me a comment and I will fill any holes in the description.
Update: The talks that I went to and I liked were these:
Can a true peer-to-peer architecture, with no central point of control, be a universal and secure solution? - talking about Ring. I believe that with TOR like location anonymization and turning that into a more basic protocol that you can piggy back anything on, from communications to pure connectivity, Ring shows a lot of promise. I was considering it as a distributed DNS architecture, so that there are no DNS servers that can be coerced to hide site IPs, for example.
Other stuff was related to WebRTC and XMPP, as communications protocols that can carry anything, but compared to what I saw with Ring, XMPP seemed obsolete
There were a lot of presentations that I wanted to go to, but there were like 10 going on at any given time. Do use the video archive link above, since it will probably hold many interesting talks that I missed
Stephen Toub wrote this document, as he calls it, but that is so full of useful information that it can be considered a reference book. A 118 pages PDF, Patterns for Parallel Programming taught me a lot of things about .NET parallel programming (although most of them I should have known already :-().
Toub is a program manager lead on the Parallel Computing Platform team at Microsoft, the smart people that gave us Task<T>, Parallel, but also await/async. The team was formed in 2006 and it had the responsibility of helping Microsoft get ready for the shift to multicore and many-core. They had broad responsibility around the company but were centered in the Developer Division because they believed the impact of this fundamental shift in how programming is done was mostly going to be on software developers.
It is important to understand that this document was last updated in 2010 and still some of the stuff there was new to me. However, some of the concepts detailed in there are timeless, like what is important to share and distribute in a parallel programming scenario. The end of the document is filled with advanced code that I would have trouble understanding even after reading this, that is why I believe you should keep this PDF somewhere close, in order to reread relevant parts when doing parallel programming. The document is free to download from Microsoft and I highly recommend it to all .NET developers out there.
Some of you may have heard of C# 6, the new version of the Microsoft .NET programming language, but what I am not certain about is that you know you can use it right now. I had expected that a new version of the language will be usable from the brand new upcoming fifth version of the .NET runtime, but actually no, you can use it right now in your projects, because the new features have been implemented in the compiler, in Visual Studio and, you have no idea how cool it is until you try, in ReSharper.
One might say: "Hell, I've seen these syntactic sugar thingies before, they are nothing but a layer over existing functionality. New version, my ass, I stick with what I know!", but you run the risk of doing as one of my junior developer colleagues did once, all red faced and angry, accusing me that I have replaced their code with question marks. I had used the null-coalescing operator to replace five line blocks like if (something == null) { ....
Let me give you some examples of these cool features, features that I have discovered not by assiduously learning them from Microsoft release documents, by but installing ReSharper - only the coolest software ever - who recommends me the changes in existing code. Let's see what it does.
Example 1: properties with getters and no setters
Classic example:
publicint Count { get { return _innerList.Count; } }
Same thing using C# 6 features?
publicint Count => _innerList.Count;
Cool or what?
Example 2: null checking in a property chain
Classic example:
if (Granddaddy!=null) { if (Daddy!=null) { if (Child!=null) { return Grandaddy.Daddy.Child.SomeStupidProperty; } } }
publicint Number { get { return _number; } set { if (_number!=value) { _number=value; OnPropertyChanged("Number"); //with some custom code you could have used a better, but slower version: //OnPropertyChanged(()=>Number); } } }
C# 6 version?
publicint Number { get { return _number; } set { if (_number!=value) { _number=value; OnPropertyChanged(nameof(Number)); // this assumes that we have a base class with a method called OnPropertyChaged, but we can already to things inline: PropertyChanged?.Invoke(this,newnew PropertyChangedEventArgs(nameof(Number)) } } }
Example 4: overriding or implementing simple methods
I don't particularly like this, but it can simplify some code when used right. Classic example:
return degrees*Math.PI/180;
C# 6 way:
//somewhere above: usingstatic System.Math;
return degrees*PI/180;
There are other more complex features as well, like special index initializers for Dictionary objects, await in catch and finally blocks, Auto-property initializers and Primary Constructors for structs. You can use all these features in any .NET version 4 and above. All you need is the new Roslyn compiler.
There are a lot of people asking around what is the difference between BindingList<T> and ObservableCollection<T> and therefore, there are a lot of answers. I am writing this entry so that next time I look it up, I save StackOverflow some bandwidth. Also, because my blog is cooler :)
So, the first difference between BindingList and ObservableCollection is that BindingList implements cascading notifications of change. If any of the items in the list implements INotifyPropertyChanged, it will accept any change from those items and expose it as a list changed event, including the index of the item that initiated the change. ObservableCollection does not do that. So BindingList is better, right?
Wrong. BindingList is not "properly supported" by WPF, say some. Why is that? Well, because BindingList, as its MSDN page says, is just "an alternative to implementing the complete IBindingList interface". Yes, you've got it. BindingList is a lazy, thin, ineffective implementation of the interface. The Missing Docs blog has a very good explanation of this. Do keep in mind that BindingList was created during the time of Windows Forms and is being used by WPF only as an afterthought.
So let's use ObservableCollection then! No. The functionalities implemented by BindingList are far superior to that of ObservableCollection. Just thinking that you must somehow handle changes of every object in the list is killing the idea.
A subtle recommendation on the same MSDN page goes like this: "the typical solutions programmer will use a class that provides data binding functionality, such as BindingSource, instead of directly using BindingList". Well, what does that mean? It means using System.Windows.Forms.BindingSource, which does about everything, since it implements IBindingListView, IBindingList, IList, ICollection, IEnumerable, ITypedList, ICancelAddNew, ISupportInitializeNotification, ISupportInitialize, ICurrencyManagerProvider and is also a subclass of Component. A bit heavy, though, isn't it?
There is more. The BindingListCollectionView page says "Specifically, IBindingList is required for BindingListCollectionView, and IBindingListView is an optional interface that gives additional sorting and filtering support.", which indicates that IBindingListView is also useful when getting a collection view for your object.
To recap: the best solution seems to be an ObservableCollection<T> that also implements IBindingListView (which itself implements IBindingList). The implementation must be scalable (getting the index of an object that causes a change in an efficient manner), though and I wonder, if I am implementing IBindingList, why should I even bother with inheriting from ObservableCollection? The same StackOverflow user seems interested only in the INotifyCollectionChanged interface for the ObservableCollection which is also implemented by IBindingListView!
Therefore, let's implement a class that explicitly implements IBindingListView and IList<T>, then publish the members we actually use! What could possibly go wrong? My idea is to store the index of an item next to the item, therefore removing the need to search for it. It seems that I must first implement an advanced List<T>, with a fast and efficient IndexOf method, then I can basically just copy paste the BindingList code and use this class of mine as the base. Unfortunately, BindingList uses Collection<T> as the base class, which itself implements IList<T>, IList, IReadOnlyList<T>. It seems I will have to implement all.
Immediately I have hit a snag. IBindingView is very difficult to implement, since it tries to filter using a string that is interpreted as a sort of DSL, so I would use a lot of reflection and weird conditions. Sorting is not much better. This is an interface invented when .NET did not support Predicates and lambda expressions, which would make sorting and filtering trivial and the subject of another post. So I go back to implementing a scalable BindingList, and just implement INotifyCollectionChanged over it.
For an implementation of IBindingView, check this out: BindingListView
Code time.
I've decided to implement the IndexOf caching as a dictionary with the objects as keys. The values are lists of integers representing all indexes of that value or object. Frankly I never realized that IndexOf for lists was not taking a start parameter, so it only returns the first occurrence of an item in the list.
There are three classes: AdvancedCollection is a fast IndexOf implementation of Collection. AdvancedBindingList is the copy pasted code of BindingList, with the base class changed from Collection to AdvancedCollection and with INotifyCollectionChanged implemented over it. SecurityUtils is only needed for the AddNew method of IBindingList and is again copy pasted from the Microsoft code. Enjoy!
I had this Javascript code that I was trying to write as tight as possible and I realized that I don't know if using "!" on an object to check if it is set to a value is slow or fast. I mean, in a strong typed language, I would compare the object with null, not use the NOT operator. So I randomly filled an array with one of five items: null, undefined, empty string, 0 and new Date(), then compared the performance of a loop checking the array items for having a value with the NOT operator versus other methods. I used Chrome 48.0.2564.109 m, Internet Explorer 11.0.9600.18163 and Firefox 44.0.2 for the tests.
Fast tally:
NOT operator: 1600/51480/1200ms
=== 0 (strong type equality): 1360/47510/2180ms
=== null : 550/45590/510ms
== with 0: 38700/63030/131940ms
== with null: 1100/48230/900ms
=== used twice(with 0 and null): 1760/69460/3500ms
typeof == 'object' (which besides the Dates also catches null): 1360/382980/1380ms
typeof === 'object' (which besides the Dates also catches null): 1370/407000/1400ms
instanceof Date: 1060/69200/600ms
Thoughts: the !/NOT operator is reasonably fast. Using normal equality can really mess up your day when it tries to transform 0 into a Date or viceversa (no, using 0 == arr[i] instead of arr[i] == 0 wasn't faster). Fastest, as expected, was the strong type equality to null. Surprising was the null equality, which catches both null and undefined and is second place. typeof was also surprising, since it not only gets the type of the object, but also compares the result with a string. Funny thing: the === comparison in the case of typeof was slower than the normal == comparison for all browsers, so probably it gets treated as a special construct.
It is obvious that both Chrome and Firefox have really optimized the Javascript engine. Internet explorer has a 18 second overhead for the loops alone (so no comparison of any kind), while the other browsers optimize it to 300ms. Sure, behind the scenes they realize that nothing happens in those loops and drop them, but still, it was a drag to wait for the result from Internet Explorer. Compared with the other huge values, the ===null comparison is insignificantly smaller than all the others on Internet Explorer, but still takes first place, while typeof took forever! Take these results with a grain of salt, though. When I was at FOSDEM I watched this presentation from Firefox when they were actually advising against this type of profiling, instead recommending special browser tools that would do that. You can watch it yourselves here.
Final conclusion: if you are checking if an object exists or not, especially if you can insure that the value of a non existent object is the same (like null), === kicks ass. The NOT operator can be used to check a user provided value, since it catches all of null, undefined, empty space or 0 and it's reasonably fast.
Here is the code:
var arr=[]; for (var i=0; i<100000; i++) { var r=parseInt(Math.random()*5); switch(r) { case 0: arr.push(null); break; case 1: arr.push(undefined); break; case 2: arr.push(''); break; case 3: arr.push(0); break; case 4: arr.push(new Date()); break; } }
var n=0; var start=performance.now(); for (var j=0; j<1000; j++) { for (var i=0; i<100000; i++) { if (!arr[i]) n++; } } var end=performance.now(); console.log('!value '+n+': '+(end-start));
n=0; start=performance.now(); for (var j=0; j<1000; j++) { for (var i=0; i<100000; i++) { if (arr[i] === 0) n++; } } end=performance.now(); console.log('value===0 '+n+': '+(end-start));
n=0; start=performance.now(); for (var j=0; j<1000; j++) { for (var i=0; i<100000; i++) { if (arr[i] === null) n++; } } end=performance.now(); console.log('value===null '+n+': '+(end-start));
n=0; start=performance.now(); for (var j=0; j<1000; j++) { for (var i=0; i<100000; i++) { if (arr[i] == 0) n++; } } end=performance.now(); console.log('value==0 '+n+': '+(end-start));
n=0; start=performance.now(); for (var j=0; j<1000; j++) { for (var i=0; i<100000; i++) { if (arr[i] == null) n++; } } end=performance.now(); console.log('value==null '+n+': '+(end-start));
The new Datetime2 data type introduced in Microsoft SQL Server 2008 has several advantages over the old Datetime type. One of them is precision in 100 nanoseconds rather than coarse milliseconds, another is that is has a larger date range. It has disadvantages, too, like a difficulty in translating it into numerical values.
There was a classic hack to CONVERT/CAST a Datetime into a Float in order to get a numerical value that you could manipulate (like convert it to an integer to get the date without time, which is now accomplished by converting it to Date, another type introduced in SQL Server 2008), but it won't work directly for a Datetime2 value.
As there are many reasons why one needs to translate a datetime into a numerical value, but I don't get into that, here is how to convert a Datetime2 value into a Float.
It computes the number of seconds with nanoseconds from 1970, divides by 86400 to get the number of days and adds 25567, which is the number of days between 1900 and 1970.
As a software developer - and by that I mean someone writing programs in C#, Javascript and so on, and occasionally using databases when something needs to be stored somewhere - I have an instinctual fear of the Arrow Anti-pattern. Therefore I really dislike stuff like NOT EXISTS(SELECT 1 FROM Something). However, recent tests have convinced me that this is the best solution for testing for existing records. I am not going to reinvent the wheel; here are some wonderful links regarding this, after which I will summarize:
Let's say you want to insert in a table all records from another source that do not already exist in the table. You have several options, but the most commonly used are:
SELECT *
FROM SourceTable
LEFT JOIN DestinationTable
ON SomeCondition
WHERE DestinationTable.Id IS NULL
and
SELECT *
FROM SourceTable
WHERE NOT EXIST(SELECT 1 FROM DestinationTable WHERE SomeCondition)
Personally I prefer the first version, for readability reasons as well as having listened to the mantra "Never do selects in selects" for all my life. However, it becomes apparent that the second version is a lot more efficient. The simple reason is that for the first example Microsoft SQL Server will first join the two tables in memory, then filter. If you have multiple combinations of records that satisfy the condition this will result in some huge memory and CPU usage, especially if you have no indexes defined and, sometimes, because you have some indexes defined. The second option uses one of the few methods guaranteed to exit, NOT EXISTS, which immediately invalidates a record at the first match.
Other options involve using the EXCEPT or INTERSECT operations in SQL, but they are not really helping. Intersecting ids, for example, then inner joining with SourceTable works, but it is somewhere in between the two solutions above and it looks like crap as well. Join hints don't help either.
The OUTPUT clause is a very useful tool in Microsoft SQL, allowing for getting automatically inserted columns in the same command as the INSERT. Imagine you have a table with an identity column and you need the generated ids as you insert new records. It would look like this:
CREATETABLE MyTable ( Id INTPRIMARYKEYIDENTITY(1, 1), Value NVARCHAR(100) )
CREATETABLE AnotherTable ( Value NVARCHAR(100), AnotherValue NVARCHAR(100), SomeConditionIsTrue BIT )
go
CREATETABLE #ids ( Id INT , AnotherValue NVARCHAR(100) )
INSERTINTO MyTable (Value) OUTPUT inserted.Id INTO #ids (id) SELECTValue FROM AnotherTable WHERE SomeConditionIsTrue = 1
-- Do something with the inserted Ids
However, what do you do if you want to also insert the column AnotherValue to the #ids table? Something like this does not work:
INSERTINTO MyTable (Value) OUTPUT inserted.Id,AnotherTable.AnotherValue INTO #ids (id,AnotherValue) SELECTValue FROM AnotherTable WHERE SomeConditionIsTrue = 1
Enter the often ignored MERGE, which can help us translate the query above into:
MERGE INTO MyTable USING ( SELECTValue , AnotherValue FROM AnotherTable WHERE SomeConditionIsTrue = 1 ) t ON 1=0 --FALSE WHENNOT MATCHED THEN INSERT (Value) VALUES (t.Value) OUTPUT Inserted.Id, t.AnotherValue INTO #ids (Id, AnotherValue);
Note the 1=0 condition so that the merge never "matches" and how the select from the first query now contains all the columns needed to be output, even if only some of them are inserted in the insert table.
This post was prompted by a StackOverflow answer that, as great as it was, didn't make it clear what to do when you get your values from a more complicated select. The answer is simple: put it all in the 'using' table.
Today we tested a web application in the new Microsoft Edge browser. To our surprize, the site failed where Internet Explorer, Chrome, Firefox and even Safari worked perfectly well. I narrowed the problem to the navigator.geolocation.getCurrentLocation which wasn't working. The site would see navigator.geolocation, ask for the current location, the user would be prompted to allow the site to access location and after that would silently fail. What I mean by that is that neither the success or the error callbacks were called, even if the options object specified one second for the timeout. I don't have access to a lot of Windows 10 machines and I assume that if a lot of people met with this problem they would invade the Internet with angry messages, but so far I've found no one having the same issue.
Bottom line: forced to take into consideration the possibility that the geolocation API would silently fail, I changed the code like this:
if (navigator.geolocation) { var timeoutInSeconds=1; var geotimeout=setTimeout(function() { handleNoGeolocation(); },timeoutInSeconds*1000+500); //plus 500 ms to allow the API to timeout normally navigator.geolocation.getCurrentPosition(function (position) { clearTimeout(geotimeout); var pos = doSomethingWith(position.coords.latitude, position.coords.longitude); }, function () { clearTimeout(geotimeout); handleNoGeolocation(); },{ enableHighAccuracy:true, timeout: timeoutInSeconds*1000 }); } else { handleNoGeolocation(); }
In the handleNoGeolocation function I've accessed the great service FreeGeoIp, that returns vague coordinates based on your IP and fell back to a static latitude, longitude pair if even this call failed.
Note: for the first time the function is called for your site, a browser dialog will appear, requesting permission to share the location. During the display of the dialog the timeout will fire, then, based on the user choice (and browser) a success/error handler will be called or nothing (like in this case), so make sure your code can handle running handleNoGeolocation followed by doSomethingWith.
I've come upon this strange Not enough storage is available to complete this operation ArgumentException when creating an instance of EventSource derived classes. This class is responsible for creating entries in Windows logs. Strangely enough, there are very few articles on the Internet connecting the class with this particular exception, so I started to investigate. One important thing to notice is that the exception is intermittent. Basically you can cycle a few times with a try/catch block and get a valid instance. That seems to indicate some sort of race condition. So far, this is the easy solution I could find. However, I really wanted to know why does it happen.
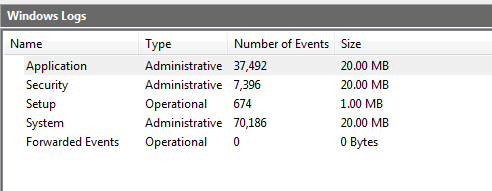
If I remove the EventSource class from the searches I get more pages reporting the same exception and one of the reasons that people say it happens is related to the size of the registry. Retrospectively it makes sense, but it never occurred to me that the system registry has a maximum size. But is that the problem? Looking with the EventViewer summary I see something like this:
Of course, the most obvious thing there is the exact size of each log category: 20.00 MB. If one right-clicks on any of the log groups and goes to Properties, the size limit for each is clearly shown and configurable. So is that the problem?
The exception is thrown almost exclusively when the logging is heavy: multiple threads trying to log stuff at the same time. Since retrying usually solves the problem, my guess is that the exception is thrown somewhere between the request for a new log entry and the process that eliminates old entries to allow for new ones. Unfortunately I don't see any configuration option for how many entries to eliminate. I would have liked to clear, let's say, 20% of the log when it is full to make this problem less relevant. Perhaps hidden in the bowels of the system registry there is a way to set this, but at this time I don't know it. Nor is it clear if I have the option to remove more of the less important events rather than just the oldest. Clearly the EventLog class in .NET supports deleting individual log entries, so this is feasible if it ever becomes a real problem.
So far, my solution is to just try again when the error is thrown:
LoggerEventSource eventSource = null; //EventSource derived class (see documentation) for (var i = 0; i < 5 && eventSource == null; i++) { try { eventSource = new LoggerEventSource(); } catch (ArgumentException) { Thread.Sleep(100); } }
Change Data Capture is a useful mechanism for tracking data changes in Microsoft SQL Server. Once you enable it for a database and some of its tables, it will create a record of any change to the data of those tables. In order to use the captured data, Microsoft recommends using the table functions provided by the mechanism, mainly [cdc].[fn_cdc_get_all_changes_dbo_<table name>] and [cdc].[fn_cdc_get_net_changes_<table name>]. However, when you use them, your very first experience might be an error that looks like this: Msg 313, Level 16, State 3, Line 20 An insufficient number of arguments were supplied for the procedure or function cdc.fn_cdc_get_all_changes_ ... . Since this is an error message everyone associates with missing a parameter for a function, one might assume that the documentation is wrong and one must add another parameter. You try adding a bogus one and you get Msg 8144, Level 16, State 3, Line 9 Procedure or function cdc.fn_cdc_get_all_changes_dbo_<table name> has too many arguments specified. which brings confusion. One hint is that if we use one less parameter than in the documentation, the error is slightly different Msg 313, Level 16, State 3, Line 9 An insufficient number of arguments were supplied for the procedure or function cdc.fn_cdc_get_all_changes_dbo_<table name>. In this error message, the tracked table name is specified in the function name, as opposed to the other where ... is used instead. What is going on?
The documentation for the function (which, as usual, nobody reads past the usage syntax and the code examples - just read the Remarks section) says this: If the specified LSN range does not fall within the change tracking timeline for the capture instance, the function returns error 208 ("An insufficient number of arguments were supplied for the procedure or function cdc.fn_cdc_get_all_changes.")., which of course is the explanation for this weird behaviour, but why and when does it happen?
The why comes from a Microsoft Connect page where an overly honest developer explains that the reason for the obscure error message is the antiquated error and function system used in T-SQL: The issue here is the inability to do raiseerror from within a function that prevents us from bubbling up meaningful error message. If one looks at the source of cdc.fn_cdc_get_all_changes_dbo_<table name>, one sees that the error is thrown from another function, a system one, called [sys].[fn_cdc_check_parameters]. Doing a select on it we get the same original error which is now slightly humourous, since it comes from a completely different function than the one in the message. Since it is a system function this time, there is no source code for it.
The when is more tricky and it shows that they didn't think this through much. First of all, whenever you send a NULL or an empty (0x0000...) value to the function as the begin or end LSN you get this error message. The code examples from Microsoft always show these mysterious LSN values being received from functions like sys.fn_cdc_get_min_lsn('<schema name>_<table name>'), sys.fn_cdc_get_max_lsn(), sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()) and so on, but they are hardly easy to understand, as they return an empty value for wrong parameters. For example, a common reason why your code fails is from getting the LSN like this: sys.fn_cdc_get_min_lsn('MyWonderfulTable') when in fact you need to use the schema in the name as well: sys.fn_cdc_get_min_lsn('dbo_MyWonderfulTable'). You have to use this syntax everywhere. Funny enough, if the tracked table is empty, you get the lowest LSN for the entire database, but if you use a wrong database name (or without the schema, or NULL, etc) you get an empty LSN. How an empty LSN is not the minimum LSN is beyond me.
My solution? Just select from the tables directly. Yeah, I know, it's bad, unrecommended by Microsoft, reinventing the wheel. But it works and I don't get weird functions messing up my flow with obscure error messages. Just remember to take a look at the cdc.* functions and see how they are written.
So, to summarize: The error message is misleading and it's all they could do within the confines of the T-SQL function error system. Remember to use the schema in the string defining the table in the cdc functions (ex: dbo_MyTable). In case you really want to be flexible, interrogate the cdc tables directly.
I had this situation where I had to execute large SQL script files and the default sqlcmd tool was throwing exceptions rather than execute them. So I created my own tool to read the scripts and execute them transactionally. Everything went smoothly, except at the end. You see, I didn't use TransactionScope.Complete from the beginning in order to see how the program would cope with a massive rollback. Not well, apparently.
The exception was thrown at rollback: Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding. I had set the TransactionOptions.Timeout to TransactionManager.MaximumTimeout and the SqlCommand.CommandTimeout to 0 (meaning never end) and I still got the exception. Apparently, the problem was the SqlConnection.ConnectTimeout which is a readonly property with a default value of 15 seconds. The value can be changed via the connection string, by adding something like Connect Timeout=36000 (10 hours) and many articles on the Internet suggest doing that. However, that is just really ugly. A better solution is to set the value of the timeout programmatically and this is how to do it:
var timeout = TimeSpan.FromHours(10); SqlConnectionStringBuilder csb = new SqlConnectionStringBuilder(connectionString); csb.ConnectTimeout = (int)timeout.TotalSeconds; connectionString = csb.ConnectionString;
As you can see, the nice SqlConnectionStringBuilder helps us validate, parse and change the values in the connection string. One can imagine other interesting uses, like adding MARS to the connection string automatically or restricting the use to a list of databases or disallowing weak passwords, etc.
Update: after another very useful comment from NULLable, I tried several new ideas:
range queries - trying to specify that the child StartIp, for example, is not only greater or equal to the parent StartIp, but also less or equal to the parent EndIp. In my case the query didn't go faster and adding new indexes as recommended in the comment made is slower. I believe it is because the range values are not static or just because clustering the start/end IP index is really way faster than any logical implementation of the search algorithm
cursor hints - obviously a very important hint that I should add to almost any cursor is LOCAL. A GLOBAL cursor can be accessed from outside the stored procedure and weird things can happen when running the stored procedure twice at the same time. NULLable recommended also STATIC READ_ONLY and FORWARD_ONLY. In truth the performance of the query doesn't really depend on the speed of the cursor, anyway, but I found an article that discusses the various cursor hints and ends up recommending LOCAL FAST_FORWARD. Check it out, it is very informative. My tests showed no real difference in this particular scenario.
RI-Tree implementation in SQL - the article that NULLable linked to is amazing! I just don't get it :) I will update this more when I gain more IQ points.
Update 2: I kind of understood the Relational Interval Tree implementation, but I couldn't find a way for it to help me. The code there creates a computed column of the same type as the IP columns then makes a BETWEEN comparison and/or a join or an apply with two table functions. I can't imagine how it could help me since the original query is basically just two BETWEEN conditions. But still a very interesting article.
I wanted to have a database of all Ripe records, in order to quickly determine the Internet Service Provider for an IP. We are discussing IPv4 only, so the structure of the table in the database looked like this:
As you can see, I translate IPs into BIGINT so that I can quickly sort and select stuff. I also added a ParentId column that represents the parent ISP, as you have some huge chunk of IPs, split and sold to other ISPs, which in turn are selling bits of the IP range they own to others and so on. The data I receive, though, is a simple text file with no hierarchical relations.
The task, therefore, is to take a table like described above, with more than four million records, and for each of them find their parent, if any.
The simplest idea is to join the table with itself like this:
SELECT rp.Id as ParentId, r.Id FROM RipeDb r INNERJOIN RipeDb rp ON rp.StartIp <= r.StartIp AND rp.EndIp >= r.EndIp AND rp.EndIp - rp.StartIp > r.EndIp - r.StartIp
This gets all ancestors for each record, so we need to use a RANK() OVER() in an inner select in order to select only the parent, but that's beyond the scope of the article.
Since we have conditions on the StartIp and EndIp columns, we need an index on them. But which?
Through trial and error, more than anything else, I realised that the best solution is a clustered index on StartIp,EndIp. That is why the first column (Id) is not marked as PRIMARY KEY in the definition of the table, because it has to look like this:
[Id] [int] PRIMARYKEYNONCLUSTEREDIDENTITY(1,1) NOT NULL
. Yes, primary keys don't have to be clustered.
But now you hit the snag. The process is EXTREMELY slow. Basically on my computer this query would end in a few days (as opposed to twice as much with a nonclustered index). What the hell is going on?
I tried several things:
JOIN hints (Merge, Loop and Hash joins) - the query optimizer seems to choose the best solution anyway
Various index combinations - nothing beats a clustered index
Taking a bunch of records and joining only them in a WHILE loop - it doesn't fill up the temp db, but it is just as slow, if not worse
At this point I kind of gave up. Days of work trying to figure out why this is going so slow reached a simple solution: 4 million records squared means 16 thousand billion comparisons. No matter how ingenious SQL would be, this will be slow. "But, Siderite, I have tables large like this and joining them is really fast!" you will say. True, with equality the joins are orders of magnitude faster. Probably there is either place for improvement in the way I used the indexes or in the way they are implemented. If you have any ideas, please let me know.
So did I solve the problem? Yes, of course, by not relying on an SQL join. Think about how the ranges are arranged. If we order the IP ranges on their start and end values, you get something like this:
For each range, the following is either a direct child or a sibling. I created a stored procedure that called itself recursively, which should have worked, but then it reached the maximum level of recursion in SQL (32 - a value that one cannot change!) and so I had to do everything myself. How? With a cursor. Here is the final code:
DECLARE @ParentIds TABLE (Id INT,StartIp BIGINT, EndIp BIGINT) DECLARE @ParentId INT DECLARE @Id INT DECLARE @StartIp BIGINT DECLARE @EndIp BIGINT DECLARE @OldParentId INT
DECLARE @i INT=0 DECLARE @c INT
DECLARE curs CURSOR LOCAL FAST_FORWARDFOR SELECT r.Id, r.StartIp, r.EndIp, r.ParentId FROM RipeDb r WHERE r.EndTime ISNULL ORDERBY StartIp ASC, EndIp DESC
OPEN curs
FETCHNEXTFROM curs INTO @Id, @StartIp, @EndIp, @OldParentId
WHILE @@FETCH_STATUS=0 BEGIN
DELETEFROM @ParentIds WHERE EndIp<@StartIp
SET @ParentId=NULL SELECTTOP 1 @ParentId=Id FROM @ParentIds ORDERBY Id DESC
SELECT @c=COUNT(1) FROM @ParentIds
IF (@i % 1000=0) BEGIN
PRINTCONVERT(NVARCHAR(100),SysUtcDatetime())+' Updated parent id for ' + CONVERT(NVARCHAR(100),@i) +' rows. ' + CONVERT(NVARCHAR(100),@c) +' parents in temp table.' RAISERROR ('', 0, 1) WITH NOWAIT
END SET @i=@i+1
IF (ISNULL(@OldParentId,-1) != ISNULL(@ParentId,-1)) BEGIN UPDATE RipeDb SET ParentId=@ParentId WHERE Id=@Id END
INSERTINTO @ParentIds VALUES(@Id,@StartIp,@EndIp)
FETCHNEXTFROM curs INTO @Id, @StartIp, @EndIp END
CLOSE curs DEALLOCATE curs
I will follow the explanation of the algorithm, for people hitting the exact issue that I had, but let me write the conclusion of this blog post: even if SQL is awesome in sorting and indexing, it doesn't mean that is the only solution. In my case, the SQL indexes proved to be a golden hammer that wasted days of my work.
So, the logic here is really simple, which makes this entire endeavour educational, but really frustrating to me:
Sort the table by start IP ascending, then end IP descending - this makes the parents come before the children in the list
Create a table variable to store the previous parents - so when you finished with a range you will automatically find yourself in its parent
Use a cursor to move through all the items and for each one:
Remove all parents that ended before the current item starts - removes siblings for the list
Get the last parent in the list - that is the current parent range
Set the parent id to be the one of the last parent
It's that deceptively simple and the query now ends in 15 minutes instead of days.
Another issue that might be interesting is that after the original import is created, the new records added to the table should be just a few. In that case, the first join and update might work faster! The next thing that I will do is count how many items I need to update and use one method or another based on that.
I needed to get all IP addresses in a range, so I applied the mask to my current IP and started to work through the minimum and maximum values of bytes to get the result. I had a code that looked like this:
for (var b = min; b <= max; b++) { //do stuff }
where min was 0 and max was 255.
The expected result: all values from 0 to 255. The result: infinitely running code. Can you spot why?
Yes, when min and max are bytes, b is also a byte, so when it gets to 255 and does b++ the value becomes 0 again. Fun, eh?
 Long story short: I thought FOSDEM 2016 was terribly non-technical.
Long story short: I thought FOSDEM 2016 was terribly non-technical.